Download

1 / 19
190 likes | 317 Vues
This paper explores the intersection of error detection mechanisms and transactional memory to achieve energy-efficient computing while ensuring reliable operations. By investigating voltage reduction effects on error rates in CPUs, specifically using AMD's FX-6100, the study demonstrates how efficient hardware support can mitigate the trade-off between energy consumption and reliability. Implementing techniques such as lightweight coordinated local checkpointing and coded processing, the research proposes a framework to enhance reliability without incurring high energy overheads, paving the way for future developments in energy-efficient systems.

E N D
Combining Error Detection and Transactional Memory for Energy-Efficient Computing below Safe Operation Margin GulayYalcin, Anita Sobe,AlexeyVoronin, Jons-TobiasWamhoff, DerinHarmanci,Adrián Cristal,OsmanUnsal, Pascal Felber,ChristofFetzerPDP2014, Turin, Italy13 February 2014
Dark Silicon Phenomenon • Number of transistors can be increased. • In order to stay within a chip’s power budget, some must remain “dark”. • One solution: Downscale the voltage.
How about Reliability? When the Vdd is reduced, the error rate increases exponentially [1]. Our goal is: Investigating the edge cases on voltage reduction while the error recovery still leads to a reduced energy consumption. [1] Dan Ernst et al. “Razor: A Low-Power Pipeline Based on Circuit-Level Timing Speculation.” In Proceedings of the 36th annual IEEE/ACM International Symposium on Microarchitecture, pages 7–18, 2003
Agenda / Overview • Motivation • Experiment: Scaling Vdd in a Real System • Basics of Reliability • Error Recovery with TM • Error Detection Schemes • Analysis • Conclusion
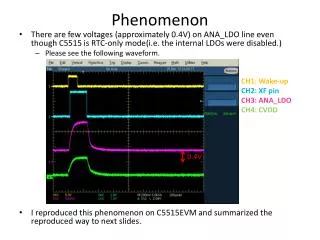
Reducing Vdd in a Real System • AMD FX-6100 • 6-core CPU • CPU-heavy execution • Every 10 seconds reduce Vdd by 12.5mV • Monitor • Incorrect Result • System Crash • Machine Check Architecture Errors are ininstruction cache (37%), execution unit (61%) and others (less than 2%). The system encounters errors which can not be corrected by MCA even only after 10% reduction in Vdd
Basics of Reliability Transactional Memory can provide a lightweight Coordinated Local Checkpoitning [2] [2] Gulay Yalcin et al. “FaulTM: Fault Tolerance Using Hardware Transactional Memory , DATE 2013
TM provides checkpointing/rollback Pn P4 Processor 1 P3 P2 Synchronize checkpoints Checkpoint (Log Area) Checkpoint (Log Area) Checkpoint (Log Area) Checkpoint (Log Area) Checkpoint (Log Area) Data-Versioning provides a synchronization mechanism between checkpoints. TM write-sets log the tentative memory updates.
Error Detection Schemes - Replication • Execute instruction streams multiple times • Compare the results of executions • Less comparison with TM. • Dual/Triple Modular Redundancy • + High Error Detection Rate • - High Energy Overhead
Error Detection Schemes-Assertions/Invariants • Assertions: Conditions referring to the current and previous state of the program. • Check the state • Adding manually or automatic • TM facilitates inserting invariants • Ex:
Error Detection Schemes - Symptoms • Monitor program executions to inspect if there is a symptom of hardware faults. • Symptoms: • Mispredictions in high confidence branches, • high OS activity, • fatal traps (e.g. undefined instruction code) • Reliability at a low cost
Error Detection Schemes- Encoded Processing • Apply software coding (ECC-like) techniques • The redundancy is added by applying arithmetic codes to the values. • Arithmetic codes: AN, ANBDmem etc. • With TM, the validation of a code word can be deferred until a TX commits. • Ex:
Analysis • Gem5 full system simulator • 1GHz in-order cores • 4 cores • X86 ISA • 64KB L1 data and instruction caches • Unified 2MB L2 cache • SPLASH2 benchmark suite.
Energy Analysis Error Detection Rate Vdd Fault Injection TX size Recovery Overhead E ≈ C x Vdd2 Error-free Overhead
Conclusion • The energy consumption of CPUs can be reduced if we have efficient hardware support for Transactional Memory and for Error Detection.
Thanks! GulayYalcin gyalcin@bsc.es