Download

1 / 20
280 likes | 847 Vues
A new initialization method for Fuzzy C- Means using Fuzzy Subtractive Clustering. Thanh Le, Tom Altman University of Colorado Denver July 19, 2011. Overview. Introduction Data clustering: approaches and current challenges fzSC

E N D
A new initializationmethod for Fuzzy C-MeansusingFuzzySubtractiveClustering Thanh Le, Tom Altman University of Colorado Denver July 19, 2011
Overview • Introduction • Data clustering: approaches and current challenges • fzSC • a novel fuzzy subtractive clustering method for FCM parameter initialization • Datasets • artificial and real datasets for testing fzSC • Experimental results • Discussion
Clustering problem • Data points are clustered based on • Similarity • Dissimilarity • Clusters are defined by • Number of clusters • Cluster boundaries & overlaps • Compactness within clusters • Separation between clusters
Clustering approaches • Hierarchical approach • Partitioning approach • Hard clustering approach • Crisp cluster boundaries • Crisp cluster membership • Soft/Fuzzy clustering approach • Soft/Fuzzy membership • Overlapping cluster boundaries • Most appropriate for the real problems
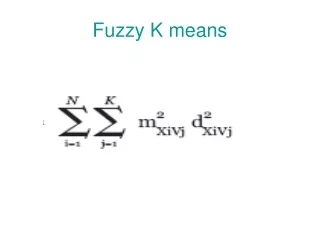
Fuzzy C-Means algorithm • The model • Features: • Fuzzy membership, soft cluster boundaries • Each data point can belong to multiple clusters, more relationship information provided
Fuzzy C-Means (contd.) • Possibility-based model • Fuzzy sets to describe clusters • Model parameters estimated using an iteration process • Rapid convergence • Challenges: • Determining the number of clusters • Initializing the partition matrix to avoid local optima
Methods for partition matrix initialization • Based on randomization • Problem: • Different randomization methods depend on different data distributions • Using heuristic algorithms: Particle Swarm • Problem: • Slow convergence because of velocity adjustment • Integrated with optimization algorithms • Problem: • Still based on other methods of partition matrix initialization
Methods for partition matrix…(contd) using Subtractive Clustering • Mountain function; the data density, , : mountain peak radius • Mountain amendment; density adjustment, , : mountain radius • Cluster candidate; the most dense data point , : threshold to stop the cluster center selection
Subtractive Clustering methodThe problems NO • Mountain peak radius? OK NO • Mountain radius? OK • Remaining density to be selected? • Computational time: O(n2)
The proposed method: fzSCfor partition matrix initialization • Generate a random fuzzy partition • Compute cluster density using histogram • Use strong uniform fuzzy partition concept • Estimate mountain function based on cluster density • Amend mountain function: • Update cluster density (step 2) • Re-estimate mountain function (step 4)
fzSC:Optimal number of clusters • The most dense data point is a cluster candidate • Data density is not much affected, say less than 0.05 of the data density removed by the mountain function amendment process. • The number of such points is less than n • , , are not required • Computational time: O(c*n)
Datasets • Artificial datasets • Finite mixture model based datasets • A manually created (MC) dataset • Data were generated using finite mixture model • Clusters were moved to have different distances among clusters • Real datasets Iris, Wine, Glass and Breast Cancer Wisconsin datasets at UC Irvine Machine Learning Repository
Visualization of fzSC result on the manually created (MC) dataset Rectangles- cluster centers of random fuzzy partition, Circles- cluster centers by fzSC
A visualization… Stars- cluster centers of random fuzzy partition, Circles- cluster centers by fzSC The utility is available online: http://ouray.ucdenver.edu/~tnle/fzsc/
Experimental results onmanually created dataset The algorithm performance on the MC dataset
Experimental results onartificial datasets Correctness ratio in determining cluster number
Experimental results onReal datasets Correctness ratio in determining cluster number
Discussion:The advantages of fzSC • Traditional subtractive clustering • , , are not required • Computational time O(c*n) vs. O(n2) • Heuristic based approaches • Rapid convergence • Escape local optima • Probability model based • Rapid convergence • No assumption of data distribution
Discussion:Future work • Combine fzSC with biological cluster validation methods and optimization algorithms for novel clustering algorithms regarding the gene expression data analysis problem.
Thank you! Questions? • We acknowledge the support from • Vietnamese Ministry of Education and Training, the 322 scholarship program.