Design and Architecture of Eclipse CPU for Irregular Local Processing
Explore the DVP system requirements, architecture philosophy, and model of computation for a flexible media processor with specialized hardware coprocessors. Discuss applications and future developments in consumer electronics.

Design and Architecture of Eclipse CPU for Irregular Local Processing
E N D
Presentation Transcript
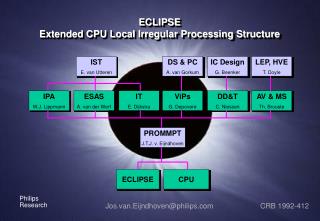
ECLIPSEExtended CPU Local Irregular Processing Structure IST E. van Utteren DS & PC A. van Gorkum IC Design G. Beenker LEP, HVE T. Doyle IPA W.J. Lippmann ESAS A. van der Werf IT E. Dijkstra ViPs G. Depovere DD&T C. Niessen AV & MS Th. Brouste PROMMPT J.T.J. v. Eijndhoven ECLIPSE CPU Jos.van.Eijndhoven@philips.com CRB 1992-412
DVP: design problem Nexperia media processors ?
DVP: application domain • High volume consumer electronics productsfuture TV, home theatre, set-top box, etc. • Media processing:audio, video, graphics, communication
DVP: SoC platform • Nexperia line of media processors for mid- to high-end consumer media processing systems is based on DVP • DVP provides template for System-on-a-Chip • DVP supports families of evolving products • DVP is part of corporate HVE strategy
DVP: system requirements • High degree of flexibility, extendability and scalability • unknown applications • new standards • new hardware blocks • High level of media processing power • hardware coprocessor support
DVP: architecture philosophy • High degree of flexibility is achieved by supporting media processing in software • High performance is achieved by providing specialized hardware coprocessors • Problem: How to mix & match hardware based and software based media processing?
A C Process B Read FIFO Execute Write DVP: model of computation Model of computation is Kahn Process Networks: • The Kahn model allows ‘plug and play’: • Parallel execution of many tasks • Configures different applications by instantiating and connecting tasks • Maintains functional correctness independent of task scheduling issues • TSSA: API to transform C programs into Kahn models
DVP: model of computation Application - parallel tasks - streams Mapping - static Architecture - programmable graph CPU coproc1 coproc2
DVP: architecture philosophy • Kahn processes (nodes) are mapped onto (co)processors • Communication channels (graph edges) are mapped onto buffers in centralized memory • Scheduling and synchronization (notification & handling of empty or full buffers) is performed by control software • Communication pattern between modules (data flow graph) is freely programmable
DVP: generic architecture • Shared, single address space, memory model • Flexible access • Transparent programming model • Physically centralized random access memory • Flexible buffer allocation • Fits well with stream processing • Single memory-bus for communication • Simple and cost effective
DVP: example architecture instantiation SDRAM Serial I/O video-in PCI bridge video-out timers I2C I/O audio-out I$ VLIW cpu audio-in D$ I$ Imagescaler MIPS cpu D$
DVP: TSSA abstraction layer TSSA-OS TSSA-Appl1 TSSA-Appl2 TM-CPU software Traditional coarse-grain TM co-processors TSSA stream data, buffered in off-chip SDRAM, synchronization with CPU interrupts
DVP: TSSA abstraction layer • Hides implementation details: • graph setup • buffer synchronization • Runs on pSOS (and other RTKs) • Provides standard API • Defines standard data formats
Outline • DVP • Eclipse DVP subsystem • Eclipse architecture • Eclipse application programming • Simulator • Status
Eclipse DVP subsystem Objective Increase flexibility of DVP systems, while maintaining cost-performance. Customer • Semiconductors: Consumer Systems (Transfer to TTI) • Consumer Electronics: Domain 2 (BG-TV Brugge) • Research Products Mid- to high-end DVP / TSSA systems: DTVs and STBs
Eclipse DVP subsystem: design problem SDRAM • Increase application flexibility through re-use of medium-grain function blocks, in HW and SW • Keep streaming data on-chip But ? • More bandwidth visible • Limited memory size • High synchronization rate • CPU unfriendly HDVO condor MPEG CPU DVP/TSSA system: • Coarse-grain ‘solid’ function blocks(reuse, HWSW ?) • Stream data buffered in off-chip memory(bandwidth, power ?)
VO DVDdecode Eclipse CPU MPEG2decode MPEG2 encode Design problem: new DVP subsystem 1394 external memory CPU
Eclipse DVP subsystem: application domain Now, target for 1st instance: • Dual MPEG2 full HD decode (1920 x 1080 @ 60i) • MPEG2 SD transcoding and HD decoding Anticipate: • Range of formats (DV, MJPEG, MPEG4) • 3D-graphics acceleration • Motion-compensated video processing
Application domain: MPEG-4 video decoding Reference Pictures Reference Pictures Reference Pictures Reference Pictures Shape Motion Compensation <220 Context Arithmetic Decoding Shape MV Prediction 0.1 90 90 Picture Reconst. MV Decoder Motion Comp. 90 MPEG-4 ES 128 90 Variable Length Decoding Inverse Scan Inverse Quantization IDCT 90 <384 800 90 DC & AC Prediction <7
Sandra Eclipse CPU MPEG-4: system level application partitioning Composition and rendering Scene description Audioobject Videoobject 3D Gfxobject Decompression De-multiplex Network layer
D$ MediaCPU I$ MPEG-4: partitioning Eclipse - SANDRA SDRAM MMI VO(SANDRA) VI VLD SRAM DCT MBS MC Eclipse
Eclipse DVP subsystem: current TSSA style TSSA TSSA-Appl1 TSSA-Appl2 TM-CPU software Traditional coarse-grain TM co-processors TSSA stream data, buffered in off-chip SDRAM, synchronization with CPU interrupts
Eclipse DVP subsystem: Eclipse tasks embedded in TSSA TSSA TSSA task on DVP HW TSSA-Appl1 TSSA-Appl2 TSSA task in SW TSSA task on Eclipse Eclipse task on HW Eclipse task in SW TSSA data streamvia off-chip memory Eclipse data streamvia on-chip memory EclipseDriver
Eclipse DVP subsystem: scale down Hierarchy in the DVP system: • Computational model which fits neatly inside DVP & TSSA Scale down from SoC to subsystem: • Limited internal distances • High data bandwidth and local storage • Fast inter-task synchronization
Outline • DVP • Eclipse DVP subsystem • Eclipse architecture • Model of computation • Generic architecture • Eclipse application programming • Simulator • Status
Eclipse architecture: model of computation Application - parallel tasks - streams Mapping - static Architecture - programmable - medium grain - multitasking CPU coproc1 coproc2
Model of computation: architecture philosophy The Kahn model allows ‘plug and play’: • Parallel execution of many tasks • Application configuration by instantiating and connecting tasks. • Functional correctness independent of task scheduling issues. Eclipse is designed to accomplish this with: • A mixture of HW and SW tasks. • High data rates (GB/s) and medium buffer sizes (KB). • Re-use of co-processors over applications through multi-tasking • Runtime application reconfiguration.
Allow proper balance in HW/SW combination Function-specific engines High Eclipse Energy efficiency DSP-CPU Low Low High Application flexibility of given silicon
Previous Kahn style architectures in PRLE CPA C-Heap Explicit synchronization Shared memory model Mixed HW/SW Data driven HW synchronization Multitasking coprocs Eclipse But ? Dynamic applications CPU in media processing But ? High performance Variable packet sizes
Outline • DVP • Eclipse DVP subsystem • Eclipse architecture • Model of computation • Generic architecture • Coprocessor shell interface • Shell communication interface • Architecture instantiation • Eclipse application programming • Simulator • Status
Generic architecture: inter-processor communication • On-chip, dedicated network for inter-processor communication: • Medium grain functions • High bandwidth (up to several GB/s) • Keep data transport on-chip • Use DVP-bus for off-chip communication only
Communication network Generic architecture: communication network CPU Coprocessor Coprocessor
Generic architecture: memory • Shared, single address space, memory model • Flexible access • Software programming model • Centralized wide memory • Flexible buffer allocation • Fits well with stream processing • Single wide memory-bus for communication • Simple and cost effective
Generic architecture: shared on-chip memory CPU Coprocessor Coprocessor Communication network Memory
Generic architecture: task level interface Partition functionality between application-dependent core and generic support. • Introduce the (co-)processor shell: • Shell is responsible for application configuration, task scheduling, data transport and synchronization • Shell (parameterized) micro-architecture is re-used for each coprocessor instance • Allow future updates of communication network while re-using (co-)processor core design • Implementations in HW or SW
Computation layer Generic support layer Shell-SW Shell-HW Communication network layer Generic architecture: layering CPU Coprocessor Coprocessor Task-level interface Shell-HW Shell-HW Communication interface Communication network Memory
Task level interface: five primitives Multitasking, synchronization, and data transport: • int GetTask( location, blocked, error, &task_info) • bool GetSpace ( port_id, n_bytes) • Read( port_id, offset, n_bytes, &byte_vector) • Write( port_id, offset, n_bytes, &byte_vector) • PutSpace ( port_id, n_bytes) GetSpaceis used for bothget_dataandget_roomcalls. PutSpaceis used forbothput_dataandput_roomcalls. The processor has the initiative, the shell answers.
a: Initial situation of ‘data tape’ with current access point: Task level interface: port IO Task A b: Inquiry action provides window on requested space: n_bytes1 c: Read/Write actions on contents: offset d: Commit action moves access point ahead: n_bytes2
Empty space Granted window for writer A B Granted window for reader Space filled with data Task level interface: communication through streams Kahn model: Task A Task B Implementation with shared circular buffer: The shell takes care that the access windows have no overlap
Task level interface: multicast Task B Forked streams: Task A Task C The task implementations are fixed (HW or SW).Application configuration is a shell responsibility. Empty space Granted window for writer C Granted window for reader C A B Granted window for reader B Space filled with data
Task level interface: characteristics • Linear (fifo) synchronization order is enforced • Random access read/write inside acquired window through offset argument • Shells operate on unformatted sequences of bytesAny semantical interpretation is left to the processor • A task is not aware of where its streams connect to,or other tasks sharing the same processor • The shell maintains the application graph structure • The shell takes care of: fifo size, fifo memory location, wrap-around addressing, caching, cache coherency, bus alignment
Task level interface: multi-tasking • Non-preemptive task scheduling • Coprocessor provides explicit task-switch moments • Task switches separate ‘processing steps’(Granularity: tens or hundreds of clock cycles) • Shell is responsible for task selection and administration • Coprocessor provides feedback to the shell on task progress int GetTask( location, blocked, error, &task_info)
Computation layer Shell-SW Shell-HW Communication network layer Generic architecture: generic support CPU Coprocessor Coprocessor Task-level interface Shell-HW Shell-HW Generic support layer Communication interface Communication network Memory
Generic support: the Shell The shell takes care of: • The application graph structure, supporting run-time reconfiguration • The local memory map and data transport(fifo size, fifo memory location, wrap-around addressing, caching, cache coherency, bus alignment) • Task scheduling and synchronization The distributed implementation: • Allows fast interaction with local coprocessor • Creates a scalable solution
Generic support: synchronization • PutSpace and GetSpace return after local update or inquiry. • Delay in messaging does not affect functional correctness. Coprocessor A Coprocessor B PutSpace( port, n ) GetSpace( port, m ) Shell Shell m space space – = n space + = n Message: putspace( gsid, n ) Communication network
Generic support: application configuration Coprocessor Shell tables are accessible through a PI-bus interface Shell Stream table Task table addr size space gsid . . . budget . . . info str_id Task_id Stream_id Communication network
Generic support: data transport caching • Translate byte-oriented coprocessor interface to wide and aligned bus transfers. • Separated caches for read and write. • Direct mapped: two adjacent words per port • Coherency is enforced as side-effect of GetSpace and PutSpace • Support automatic prefetching and preflushing