Memory Mountain and Cache Impact Analysis
Explore the Memory Mountain's impact on read bandwidth and cache performance. Learn how caches influence program efficiency and memory system capabilities. Implement matrix multiplication techniques for enhanced program performance.


Memory Mountain and Cache Impact Analysis
E N D
Presentation Transcript
Outline • Cache mountain • Matrix multiplication • Suggested Reading: 6.6, 6.7
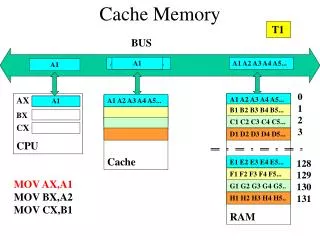
6.6 Putting it Together: The Impact of Caches on Program Performance 6.6.1 The Memory Mountain
The Memory Mountain P512 • Read throughput (read bandwidth) • The rate that a program reads data from the memory system • Memory mountain • A two-dimensional function of read bandwidth versus temporal and spatial locality • Characterizes the capabilities of the memory system for each computer
Memory mountain main routineFigure 6.41 P513 /* mountain.c - Generate the memory mountain. */ #define MINBYTES (1 << 10) /* Working set size ranges from 1 KB */ #define MAXBYTES (1 << 23) /* ... up to 8 MB */ #define MAXSTRIDE 16 /* Strides range from 1 to 16 */ #define MAXELEMS MAXBYTES/sizeof(int) int data[MAXELEMS]; /* The array we'll be traversing */
Memory mountain main routine int main() { int size; /* Working set size (in bytes) */ int stride; /* Stride (in array elements) */ double Mhz; /* Clock frequency */ init_data(data, MAXELEMS); /* Initialize each element in data to 1 */ Mhz = mhz(0); /* Estimate the clock frequency */
Memory mountain main routine for (size = MAXBYTES; size >= MINBYTES; size >>= 1) { for (stride = 1; stride <= MAXSTRIDE; stride++) printf("%.1f\t", run(size, stride, Mhz)); printf("\n"); } exit(0); }
Memory mountain test functionFigure 6.40 P512 /* The test function */ void test (int elems, int stride) { int i, result = 0; volatile int sink; for (i = 0; i < elems; i += stride) result += data[i]; sink = result; /* So compiler doesn't optimize away the loop */ }
Memory mountain test function /* Run test (elems, stride) and return read throughput (MB/s) */ double run (int size, int stride, double Mhz) { double cycles; int elems = size / sizeof(int); test (elems, stride); /* warm up the cache */ cycles = fcyc2(test, elems, stride, 0); /* call test (elems,stride) */ return (size / stride) / (cycles / Mhz); /* convert cycles to MB/s */ }
The Memory Mountain • Data • Size • MAXBYTES(8M) bytes or MAXELEMS(2M) words • Partially accessed • Working set: from 8MB to 1KB • Stride: from 1 to 16
Ridges of temporal locality • Slice through the memory mountain with stride=1 • illuminates read throughputs of different caches and memory Ridges: 山脊
A slope of spatial locality • Slice through memory mountain with size=256KB • shows cache block size.
6.6 Putting it Together: The Impact of Caches on Program Performance 6.6.2 Rearranging Loops to Increase Spatial Locality
Matrix Multiplication ImplementationFigure 6.45 (a) P518 /* ijk */ for (i=0; i<n; i++) { for (j=0; j<n; j++) { c[i][j] = 0.0; for (k=0; k<n; k++) c[i][j] += a[i][k] * b[k][j]; } } O(n3)adds and multiplies Each n2 elements of A and B is read n times
Matrix Multiplication P517 • Assumptions: • Each array is an nn array of double, with size 8 • There is a single cache with a 32-byte block size ( B=32 ) • The array size n is so large that a single matrix row does not fit in the L1 cache • The compiler stores local variables in registers, and thus references to local variables inside loops do not require any load and store instructions.
Matrix MultiplicationFigure 6.45 (a) P518 /* ijk */ for (i=0; i<n; i++) { for (j=0; j<n; j++) { sum = 0.0; for (k=0; k<n; k++) sum += a[i][k] * b[k][j]; c[i][j] = sum; } } Variable sum held in register
Column- wise Fixed Matrix multiplication (ijk) • Misses per Inner Loop Iteration: ABC 0.25 1.0 0.0 /* ijk */ for (i=0; i<n; i++) { for (j=0; j<n; j++) { sum = 0.0; for (k=0; k<n; k++) sum += a[i][k] * b[k][j]; c[i][j] = sum; } } Inner loop: (*,j) (i,j) (i,*) A B C Row-wise 1) (AB) Figure 6.46 P519
Row-wise Column- wise Fixed Matrix multiplication (jik)Figure 6.45 (b) P518 /* jik */ for (j=0; j<n; j++) { for (i=0; i<n; i++) { sum = 0.0; for (k=0; k<n; k++) sum += a[i][k] * b[k][j]; c[i][j] = sum } } Inner loop: (*,j) (i,j) (i,*) A B C • Misses per Inner Loop Iteration: • ABC • 0.25 1.0 0.0 1) (AB) Figure 6.46 P519
Row-wise Row-wise Fixed Matrix multiplication (kij)Figure 6.45 (e) P518 /* kij */ for (k=0; k<n; k++) { for (i=0; i<n; i++) { r = a[i][k]; for (j=0; j<n; j++) c[i][j] += r * b[k][j]; } } Inner loop: (i,k) (k,*) (i,*) A B C 3) (BC) • Misses per Inner Loop Iteration: • ABC • 0.0 0.25 0.25 Figure 6.46 P519
Row-wise Row-wise Fixed Matrix multiplication (ikj)Figure 6.45 (f) P518 /* ikj */ for (i=0; i<n; i++) { for (k=0; k<n; k++) { r = a[i][k]; for (j=0; j<n; j++) c[i][j] += r * b[k][j]; } } Inner loop: (i,k) (k,*) (i,*) A B C 3) (BC) • Misses per Inner Loop Iteration: • ABC • 0.0 0.25 0.25 Figure 6.46 P519
Column - wise Column- wise Fixed Matrix multiplication (jki)Figure 6.45 (c) P518 /* jki */ for (j=0; j<n; j++) { for (k=0; k<n; k++) { r = b[k][j]; for (i=0; i<n; i++) c[i][j] += a[i][k] * r; } } Inner loop: (*,k) (*,j) (k,j) A B C 2) (AC) • Misses per Inner Loop Iteration: • ABC • 1.0 0.0 1.0 Figure 6.46 P519
Column- wise Column- wise Fixed Matrix multiplication (kji)Figure 6.45 (d) P518 /* kji */ for (k=0; k<n; k++) { for (j=0; j<n; j++) { r = b[k][j]; for (i=0; i<n; i++) c[i][j] += a[i][k] * r; } } Inner loop: (*,k) (*,j) (k,j) A B C 2) (AC) • Misses per Inner Loop Iteration: • ABC • 1.0 0.0 1.0 Figure 6.46 P519
Pentium matrix multiply performanceFigure 6.47 (d) P519 2) (AC) 2) 3) 1) 3) (BC) 1) (AB)
Pentium matrix multiply performance • Notice that miss rates are helpful but not perfect predictors. • Code scheduling matters, too.
Summary of matrix multiplication • ijk (& jik): • 2 loads, 0 stores • misses/iter = 1.25 • kij (& ikj): • 2 loads, 1 store • misses/iter = 0.5 • jki (& kji): • 2 loads, 1 store • misses/iter = 2.0 for (i=0; i<n; i++) { for (j=0; j<n; j++) { sum = 0.0; for (k=0; k<n; k++) sum += a[i][k] * b[k][j]; c[i][j] = sum; } } for (k=0; k<n; k++) { for (i=0; i<n; i++) { r = a[i][k]; for (j=0; j<n; j++) c[i][j] += r * b[k][j]; } } for (j=0; j<n; j++) { for (k=0; k<n; k++) { r = b[k][j]; for (i=0; i<n; i++) c[i][j] += a[i][k] * r; } } 1) (AB) 3) (BC) 2) (AC)
6.6 Putting it Together: The Impact of Caches on Program Performance 6.6.3 Using Blocking to Increase Temporal Locality
Improving temporal locality by blocking P520 • Example: Blocked matrix multiplication • “block” (in this context) does not mean “cache block”. • Instead, it mean a sub-block within the matrix. • Example: N = 8; sub-block size = 4
A11 A12 A21 A22 B11 B12 B21 B22 C11 C12 C21 C22 = X Key idea: Sub-blocks (i.e., Axy) can be treated just like scalars. C11 = A11B11 + A12B21 C12 = A11B12 + A12B22 C21 = A21B11 + A22B21 C22 = A21B12 + A22B22 Improving temporal locality by blocking
Blocked matrix multiply (bijk)Figure 6.48 P521 for (jj=0; jj<n; jj+=bsize) { for (i=0; i<n; i++) for (j=jj; j < min(jj+bsize,n); j++) c[i][j] = 0.0; for (kk=0; kk<n; kk+=bsize) { for (i=0; i<n; i++) { for (j=jj; j < min(jj+bsize,n); j++) { sum = 0.0 for (k=kk; k < min(kk+bsize,n); k++) { sum += a[i][k] * b[k][j]; } c[i][j] += sum; } } } }
Blocked matrix multiply analysis • Innermost loop pair multiplies a 1 X bsize sliver of A by a bsize X bsize block of B and accumulates into 1 X bsize sliver of C • Loop over i steps through n row slivers of A & C, using same B Sliver: 长条
for (i=0; i<n; i++) { for (j=jj; j < min(jj+bsize,n); j++) { sum = 0.0 for (k=kk; k < min(kk+bsize,n); k++) { sum += a[i][k] * b[k][j]; } c[i][j] += sum; } Innermost Loop Pair kk jj jj kk i i A B C Update successive elements of sliver row sliver accessed bsize times block reused n times in succession Blocked matrix multiply analysis Figure 6.49 P522
Pentium blocked matrix multiply performanceFigure 6.50 P523 2) 3) 1)
6.7 Putting it Together: Exploring Locality in Your Programs
Techniques P523 • Focus your attention on the inner loops • Try to maximize the spatial locality in your programs by reading data objects sequentially, in the order they are stored in memory • Try to maximize the temporal locality in your programs by using a data object as often as possible once it has been read from memory • Miss rates, the number of memory accesses