ACID
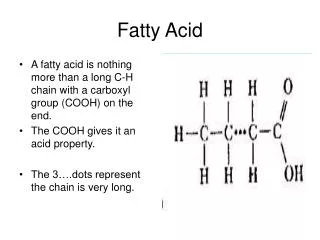
ACID. A transaction is atomic -- all or none property. If it executes partly, an invalid state is likely to result. A transaction, may change the DB from a consistent state to another consistent state. Otherwise it is rejected (aborted).


ACID
E N D
Presentation Transcript
ACID • A transaction is atomic --all or none property. If it executes partly, an invalid state is likely to result. • A transaction, may change the DB from a consistent state to another consistent state. Otherwise it is rejected (aborted). • Concurrent execution of transactions may lead to inconsistency – each transaction must appear to be executed in isolation (next chapter) • The effect of a committed transaction is durable i.e. the effect on DB of a transaction must never be lost, once the transaction has completed. • ACID: Properties of a transaction: Atomicity, Consistency, Isolation, and Durability
Primitive DB Op’s of Transactions • INPUT(X)≡ copy the disk block containing the database element X to a memory buffer • READ(X,t)≡ assign the value of buffer X to local variable t • WRITE(X,t)≡ copy the value of t to buffer X • OUTPUT(X)≡ copy the block containing X from its buffer (in main memory) to disk
Example (Cont’d) Action t Buff A Buff B A in HD B in HD Read(A,t) 8 8 8 8 t:=t*2 16 8 8 8 Write(A,t) 16 16 8 8 Read(B,t) 8 16 8 8 8 t:=t*2 16 16 8 8 8 Write(B,t) 16 16 16 8 8 Output(A) 16 16 16 16 8 Output(B) 16 16 16 16 16 Problem: what happens if there is a system failure just before OUTPUT(B)?
Undo Logging • Create a log of all “important actions.” • A log is a sequential file opened for appending only <START T> -- transaction T started. <T,X,OldX> -- database element X was modified; it used to have the value OldX <COMMIT T> -- transaction T has completed <ABORT T> -- Transaction T couldn’t complete successfully. • Intention for undo logging: • If there is a crash before transaction finishes, the log will tell us how to restore old values for any DB element X changed on disk.
Undo Logging (Cont’d) Two rules of Undo Logging: • U1: Log records for a DB element X must be on disk before any database modification to X appears on disk. • U2: If a transaction T commits, then the log record <COMMIT T> must be written to disk only after all database elements changed by T are written to disk. • In order to force log records to disk, the log manager needs a FLUSH LOG command that tells the buffer manager to copy to disk any log blocks that haven’t previously been copied to disk or that have been changed since they were last copied.
Example: Action t Buff A Buff B A in HD B in HD Log Read(A,t) 8 8 8 8 <Start T> t:=t*2 16 8 8 8 Write(A,t) 16 16 8 8 <T,A,8> Read(B,t) 8 16 8 8 8 t:=t*2 16 16 8 8 8 Write(B,t) 16 16 16 8 8 <T,B,8> Flush Log Output(A) 16 16 16 16 8 Output(B) 16 16 16 16 16 <Commit T> Flush Log
Abort Actions • Sometimes a transaction T cannot complete because for e.g.: • It detects an error condition such as faulty data, divide by zero, etc. • It gets involved in a deadlock, competing for resources & data with other transactions. • If so, T aborts; it does not write any of its DB modifications to disk; A log record <ABORT T> is created
Recovery With Undo Logging 1. Examine the log to identify all transactions T such that <START T> appears in the log, but neither <COMMIT T> nor <ABORT T> does. • Call such transactions incomplete. 2. Examine each log entry <T, X, v> a) If T isn’t an incomplete transaction, do nothing. b) If T is incomplete, restore the old value of X In what order? From most recent to earliest. 3. For each incomplete transaction T add <ABORT T> to the log, and flush the log. • What about the transactions that had already <ABORT T> in the log? • We do nothing about them. If T aborted, then the effect on the DB should have been restored anyway.
Example • If there is crash before OUTPUT(B) then this would result in T being identified as incomplete. • We would find <T,A,8> in the log and write A = 8 to the DB. • We also would find <T,B,8> in the log and “restore” B to value 8, although B has already this value. • Problem: What would happen if there were another system error during recovery? • Not really a problem. Recovery steps are idempotent, I.e. repeating them many times has exactly the same effect as performing them once. • The same applies for the other logging methods as well.
Checkpointing • Problem: in principle, recovery requires looking at the entire log. • Simple solution: occasional checkpoint operation during which we: • Stop accepting new transactions. • Wait until all current transactions commit or abort and have written a Commit or Abort log record • Flush the log to disk • Enter a <CKPT> record in the log and flush the log again • Resume accepting transactions • If recovery is necessary, we know that all transactions prior to a <CKPT> record have committed or aborted and need not be undone
Example of an Undo log <START T1> <T1,A,5> <START T2> <T2,B,10> decide to do a checkpoint <T2,C,15> <T1,D,20> <COMMIT T1> <COMMIT T2> <CKPT> we may now write the CKPT record <START T3> <T3,E,25> <T3,F,30> If a crash occurs at this point?
Nonquiescent Checkpoint (NQ CKPT) • Problem: we may not want to stop transactions from entering the system. • Solution: 1. Write a record <START CKPT(T1,...,Tk)> to log and flush to disk, where Ti’s are all current “active” transactions. 2. Wait until all Ti’s commit or abort, but do not prohibit new transactions. 3. When all T1…Tk are “done”, write the record <END CKPT> to log and flush.
Recovery with NQ CKPT First case: • If the crash follows <END CKPT>, • Then we can restrict recovery to transactions that started after the <START CKPT>. Second case: • If the crash occurs between <START CKPT> and <END CKPT>, we need to undo: 1. All transactions T on the list associated with <START CKPT> with no <COMMIT T>. 2. All transactions T with <START T> after the <START CKPT> but with no <COMMIT T>. i.e. 1+2undo any incomplete transaction that is on the CKPT list or started after <START CKPT>.
Example of NQ Undo Log <START T1> <T1,A,5> <START T2> <T2,B,10> <START CKPT (T1,T2)> <T2,C,15> <START T3> <T1,D,20> <COMMIT T1> <T3,E,25> <COMMIT T2> <END CKPT> <T3,F,30> A crash occurs at this point What if we have a crash right after <T3,E,25>?
Undo Drawback • We cannot commit a transaction without first writing all its changed data to disk. • Sometime we can save disk I/O if we let changes to the DB reside only in main memory for a while; • …as long as we can fix things up in the event of a crash…
Redo Logging • Idea: Commit (log record appears on disk) before writing data to disk. • Redolog entries contain the new values: • <T,X,NewX>= “transaction T modified X and the new value is NewX” • Redo logging rule: • R1. Before modifying DB element X on disk, all log entries (including <COMMIT T>) must be written to log (in disk).
Example: Action t Buff A Buff B A in HD B in HD Log Read(A,t) 8 8 8 8 <Start T> t:=t*2 16 8 8 8 Write(A,t) 16 16 8 8 <T,A,16> Read(B,t) 8 16 8 8 8 t:=t*2 16 16 8 8 8 Write(B,t) 16 16 16 8 8 <T,B,16> <Commit T> Flush Log Output(A) 16 16 16 16 8 Output(B) 16 16 16 16 16
Recovery for Redo Logging • Identify committed transactions. • Examine the log forward, from earliest to latest. • Consider only the committed transactions, T. • For each <T, X, v> in the log do: WRITE(X,v); OUTPUT(X); Note 1: Uncommitted transactions will have no effect on the DB (unlike in undo logging) This because none of the changes of an uncommitted T have reached the disk Note 2: “Redoing” starts from the head of the log; In effect, each data item X will have the value written by the last transaction in the log that changed X.
Checkpointing for Redo Logging • The key action that we must take between the start and end of checkpoint is to write to disk all the dirty buffers. • Dirty buffers are those that have been changed by committed transactions but not written to disk. • Unlike in the undo case, we don’t need to wait for active transactions to finish (in order to write <END CKPT>). • However, we wait for copying dirty buffers of the committed transactions.
Checkpointing for Redo (Cont’d) 1.Write a <START CKPT(T1,...,Tk )> record to the log, where Ti’s are all active transactions. 2. Write to disk all the dirty buffers of transactions that had already committed when the START CKPT was written to log. 3. Write an <END CKPT> record to log.
Checkpointing for Redo (Cont’d) <START T1> <T1,A,5> <START T2> <COMMIT T1> <T2,B,10> <START CKPT(T2)> <T2,C,15> <START T3> <T3,D,20> <END CKPT> <COMMIT T2> <COMMIT T3> The buffer containing value A might be dirty. If so, copy it to disk. Then write <END CKPT>. During this period three other actions took place.
Recovery with Ckpt. Redo Two cases: • If the crash follows <END CKPT>, we can restrict ourselves to transactions that began after the <START CKPT>and those in the START list. • This is because we know that, in this case, every value written by committed transactions, before START CKPT(…), is now in disk. 2. If the crash occurs between <START CKPT> and <END CKPT>, then go and find the previous <END CKPT> and do the same as in the first case. • This is because we are not sure that committed transactions before START CKPT(…) have their changes in disk.