Understanding CPU Architecture: Pipelines, ALUs, and Execution Mechanisms
940 likes | 1.07k Vues
This comprehensive guide explores the evolution of CPU architectures, focusing on key concepts such as instruction set architectures, single-cycle and multi-cycle CPUs, and microprogramming. The discussion incorporates pipelining techniques that enhance performance by increasing instruction throughput while addressing potential stalls and hazards. Readers will gain insights into out-of-order execution, superscalar machines, and the impact of structural and data hazards on CPU efficiency. Learn how these architectures are structured and optimized for modern computational needs.

Understanding CPU Architecture: Pipelines, ALUs, and Execution Mechanisms
E N D
Presentation Transcript
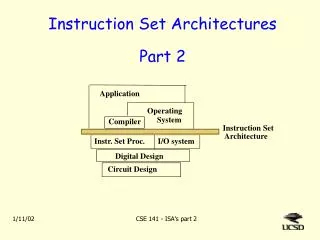
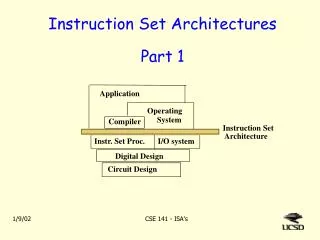
The Story so far: • Instruction Set Architectures • Performance issues • ALUs • Single Cycle CPU • Multicycle CPU: datapath; control • Microprogramming • Exceptions • Pipelining • Basic datapath • Control for pipelining • Structural hazards: memory • Data hazards: forwarding, stalling • Branching hazards: prediction, exceptions • Out of order execution, speculative execution • Superscalar machines etc. Tarun Soni, Summer ‘03
CPU Pipelining Tarun Soni, Summer ‘03
2 AM 12 6 PM 1 8 7 11 10 9 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 T a s k O r d e r Time A A B B C C D D Laundry Tarun Soni, Summer ‘03
Pipelining Lessons • Pipelining doesn’t help latency of single task, it helps throughput of entire workload • Multiple tasks operating simultaneously using different resources • Potential speedup = Number pipe stages • Pipeline rate limited by slowest pipeline stage • Unbalanced lengths of pipe stages reduces speedup • Time to “fill” pipeline and time to “drain” it reduces speedup • Stall for Dependences Tarun Soni, Summer ‘03
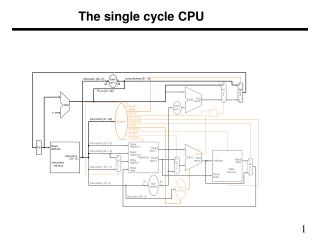
Single Cycle CPU Tarun Soni, Summer ‘03
Multicycle CPU IF ID Ex Mem WB Tarun Soni, Summer ‘03
Multi-Cycle CPU Tarun Soni, Summer ‘03
Ifetch Reg/Dec Exec Mem Wr Ifetch Reg/Dec Exec Mem Wr Ifetch Reg/Dec Exec Wr Instruction Latencies Single-Cycle CPU Load Multiple Cycle CPU Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Load Add Tarun Soni, Summer ‘03
Ifetch Reg/Dec Exec Mem Wr The Multicycle Processor The Five Stages of Load Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Load • Ifetch: Instruction Fetch • Reg/Dec: Registers Fetch and Instruction Decode • Exec: Calculate the memory address • Mem: Read the data from the Data Memory • Wr: Write the data back to the register file Tarun Soni, Summer ‘03
Pipelining • Improve perfomance by increasing instruction throughput Ideal speedup is number of stages in the pipeline. Do we achieve this? Tarun Soni, Summer ‘03
Ifetch Reg Exec Mem Wr Ifetch Reg Exec Mem Ifetch Ifetch Reg Exec Mem Wr Ifetch Reg Exec Mem Wr Ifetch Reg Exec Mem Wr Single Cycle, Multiple Cycle, vs. Pipeline Cycle 1 Cycle 2 Clk Single Cycle Implementation: Load Store Waste Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9 Cycle 10 Clk Multiple Cycle Implementation: Load Store R-type Pipeline Implementation: Load Store R-type Tarun Soni, Summer ‘03
IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB IFetch Dcd Exec Mem WB Conventional Pipelined Execution Representation Time Program Flow • Suppose we execute 100 instructions, CPI=4.6, 45ns vs. 10ns cycle time. • Single Cycle Machine: 45 ns/cycle x 1 CPI x 100 inst = 4500 ns • Multicycle Machine: 10 ns/cycle x 4.6 CPI (due to inst mix) x 100 inst = 4600 ns • Ideal pipelined machine: 10 ns/cycle x (1 CPI x 100 inst + 4 cycle drain) = 1040 ns Tarun Soni, Summer ‘03
Basic Idea • What do we need to add to actually split the datapath into stages? Tarun Soni, Summer ‘03
Graphically Representing Pipelines Memory Read Reg Write Can help with answering questions like: • how many cycles does it take to execute this code? • what is the ALU doing during cycle 4? • use this representation to help understand datapaths Tarun Soni, Summer ‘03
IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU Pipelined execution CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 CC9 IF ID EX MEM WB lw IF ID EX MEM WB lw lw lw lw steady state Tarun Soni, Summer ‘03
IM Reg DM Reg ALU ALU Mixed Instructions in Pipeline CC1 CC2 CC3 CC4 CC5 CC6 lw IM Reg Reg add Tarun Soni, Summer ‘03
IM Reg DM Reg ALU Principles of pipelining • All instructions that share a pipeline must have the same stages in the same order. • therefore, add does nothing during Mem stage • sw does nothing during WB stage • All intermediate values must be latched each cycle. • There is no functional block reuse • So, like the single cycle design, we now need two adders + one ALU IF ID EX MEM WB Tarun Soni, Summer ‘03
Pipelined Datapath Instruction Fetch Instruction Decode/ Register Fetch Execute/ Address Calculation Memory Access Write Back registers! Tarun Soni, Summer ‘03
Pipelined Datapath add $10, $1, $2 Instruction Decode/ Register Fetch Execute/ Address Calculation Memory Access Write Back Tarun Soni, Summer ‘03
Pipelined Datapath lw $12, 1000($4) add $10, $1, $2 Execute/ Address Calculation Memory Access Write Back Tarun Soni, Summer ‘03
Pipelined Datapath sub $15, $4, $1 lw $12, 1000($4) add $10, $1, $2 Memory Access Write Back Tarun Soni, Summer ‘03
Pipelined Datapath Instruction Fetch sub $15, $4, $1 lw $12, 1000($4) add $10, $1, $2 Write Back Tarun Soni, Summer ‘03
Pipelined Datapath Instruction Fetch Instruction Decode/ Register Fetch sub $15, $4, $1 lw $12, 1000($4) add $10, $1, $2 Tarun Soni, Summer ‘03
Pipelined Datapath Instruction Fetch Instruction Decode/ Register Fetch Execute/ Address Calculation sub $15, $4, $1 lw $12, 1000($4) Tarun Soni, Summer ‘03
What about control? • can’t use microprogram • FSM not really appropriate • Combinational Logic! • signals generated once, but follow instruction through the pipeline control instruction IF/ID ID/EX EX/MEM MEM/WB Tarun Soni, Summer ‘03
What about control? Tarun Soni, Summer ‘03
Pipelined system with control logic Tarun Soni, Summer ‘03
IM Reg DM Reg ALU ALU Pipelined execution: mixed instructions? • Remember mixed instructions? CC1 CC2 CC3 CC4 CC5 CC6 lw IM Reg Reg add Tarun Soni, Summer ‘03
Can pipelining get us into trouble? • Yes:Pipeline Hazards • structural hazards: attempt to use the same resource two different ways at the same time • data hazards: attempt to use item before it is ready • instruction depends on result of prior instruction still in the pipeline • control hazards: attempt to make a decision before condition is evaulated • branch instructions • Can always resolve hazards by waiting • Worst case the machine behaves like a multi-cycle machine! • pipeline control must detect the hazard • take action (or delay action) to resolve hazards Tarun Soni, Summer ‘03
Mem ALU Mem Mem Reg Reg ALU Mem Mem Reg Reg ALU ALU Mem Mem Reg Reg ALU Single Memory is a Structural Hazard Time (clock cycles) Data Read I n s t r. O r d e r Mem Reg Reg Load Instr 1 Instr 2 Mem Mem Reg Reg Instr 3 Instr 4 Instruction Fetch Detection is easy in this case!(right half highlight means read, left half write) Tarun Soni, Summer ‘03
Data Hazards • Suppose initially, register i holds the number 2i • $10 <= 20 • $11 <= 22 • $3 <= 6 • $7 <= 14 • $8 <= 16 • What happens when... add $3, $10, $11 - this should add 20 + 22, putting result 42 into r3 lw $8, 50($3) - this should load r8 from memory location 42+50 = 92 sub $11, $8, $7 - this should subtract 14 from that just-loaded value Tarun Soni, Summer ‘03
Data Hazards add $3, $10, $11 Execute/ Address Calculation Memory Access Write Back lw $8, 50($3) 20 22 Tarun Soni, Summer ‘03
Data Hazards sub $11, $8, $7 lw $8, 50($3) add $3, $10, $11 Memory Access Write Back Ooops! This should have been “42”! But register 3 didn’t get updated yet. 6 16 20 22 42 50 Tarun Soni, Summer ‘03
Data Hazards add $10, $1, $2 sub $11, $8, $7 lw $8, 50($3) • add $3, $10, $11 Write Back And this should be value from memory (which hasn’t even been loaded yet). Recall: this should have been “92” 16 14 6 50 56 42 Tarun Soni, Summer ‘03
IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU ALU Data Hazards • When a result is needed in the pipeline before it is available, a “data hazard” occurs. R2 Available CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 sub $2, $1, $3 and $12, $2, $5 R2 Needed or $13, $6, $2 add $14, $2, $2 IM Reg DM sw $15, 100($2) Tarun Soni, Summer ‘03
Im ALU Im ALU Im Dm Reg Reg ALU Data Hazard on r1: • Dependencies backwards in time are hazards Time (clock cycles) IF ID/RF EX MEM WB add r1,r2,r3 Reg Reg ALU Im Dm I n s t r. O r d e r sub r4,r1,r3 Dm Reg Reg Dm Reg Reg and r6,r1,r7 Im Dm Reg Reg or r8,r1,r9 ALU xor r10,r1,r11 Tarun Soni, Summer ‘03
Data Hazards • In Software • inserting independent instructions • In Hardware • inserting bubbles (stalling the pipeline) • data forwarding Data Hazards are caused by instruction dependences. For example, the add is data-dependent on the subtract: subi $5, $4, #45 add $8, $5, $2 Tarun Soni, Summer ‘03
IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU Handling Data Hazards Transparent register file eliminates one hazard. Use latches rather than flip-flops in Reg file • First half-cycle of cycle 5: register 2 loaded • Second half-cycle: new value is read into pipeline state CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 R2 Available sub $2, $1, $3 and $12, $6, $5 or $13, $6, $8 add $14, $2, $2 Tarun Soni, Summer ‘03
IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU Handling Data Hazards: Software CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 sub $2, $1, $3 nop nop add $12, $2, $5 Insert enough no-ops (or other instructions that don’t use register 2) so that data hazard doesn’t occur, Remember the “out-of-order” execution on the Power4 from last class? Tarun Soni, Summer ‘03
Handling Data Hazards: Software sub $2, $1,$3 and $4, $2,$5 or $8, $2,$6 add $9, $4,$2 slt $1, $6,$7 Assume a standard 5-stage pipeline, How many data-hazards in this piece of code? How many no-ops do you need? Where? What if you are allowed to execute out-of-order? Tarun Soni, Summer ‘03
IM Reg DM Reg Bubble Bubble Handling Data Hazards: Hardware: Bubbles CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 sub $2, $1, $3 IM Reg DM Reg and $12, $2, $5 IM Reg DM Reg or $13, $6, $2 IM Reg DM add $14, $2, $2 Tarun Soni, Summer ‘03
Handling Data Hazards: Hardware: Pipeline Stalls • To insure proper pipeline execution in light of register dependences, we must: • Detect the hazard • Stall the pipeline • prevent the IF and ID stages from making progress • the ID stage because we can’t go on until the dependent instruction completes correctly • the IF stage because we do not want to lose any instructions. • insert“no-ops” into later stages Tarun Soni, Summer ‘03
Handling Data Hazards: Hardware: Pipeline Stalls How to stall a pipeline in two quick steps ! • Prevent the IF and ID stages from proceeding • don’t write the PC (PCWrite = 0) • don’t rewrite IF/ID register (IF/IDWrite = 0) • Insert “nops” • set all control signals propagating to EX/MEM/WB to zero Tarun Soni, Summer ‘03
Handling Data Hazards: Hardware: Pipeline Stalls Tarun Soni, Summer ‘03
IM Reg DM Reg ALU IM Reg DM Reg ALU ID/EX EX/MEM MEM/WB Registers Data Memory ALU 0 1 Handling Data Hazards: Forwarding add $2, $3, $4 or $5, $3, $2 We could avoid stalling if we could get the ALU output from “add” to ALU input for the “or” Tarun Soni, Summer ‘03
Handling Data Hazards: Forwarding EX Hazard: if (EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) ForwardA = 10 if (EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt)) ForwardB = 10 (similar for the MEM stage) Tarun Soni, Summer ‘03
Handling Data Hazards: Forwarding • Forwarding (just shown) handles two types of data hazards • EX hazard • MEM hazard • We’ve already handled the third type (WB) hazard by using a transparent reg file • if the register file is asked to read and write the same register in the same cycle, the reg file allows the write data to be forwarded to the output. Tarun Soni, Summer ‘03
Im ALU Im ALU Im Dm Reg Reg ALU Data Hazard Solution: • “Forward” result from one stage to another • “or” OK if define read/write properly Time (clock cycles) IF ID/RF EX MEM WB add r1,r2,r3 Reg Reg ALU Im Dm I n s t r. O r d e r sub r4,r1,r3 Dm Reg Reg Dm Reg Reg and r6,r1,r7 Im Dm Reg Reg or r8,r1,r9 ALU xor r10,r1,r11 Tarun Soni, Summer ‘03
IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU ALU Data Hazard Solution: With Forwarding CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 sub $2, $1, $3 and $6, $2, $5 or $13, $6, $2 add $14, $2, $2 IM Reg DM sw $15, 100($2) Tarun Soni, Summer ‘03
IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU ALU Data Hazard Solution: What about this stream? CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 lw $2, 10($1) and $12, $2, $5 or $13, $6, $2 add $14, $2, $2 IM Reg DM sw $15, 100($2) • Solve this using forwarding? Tarun Soni, Summer ‘03