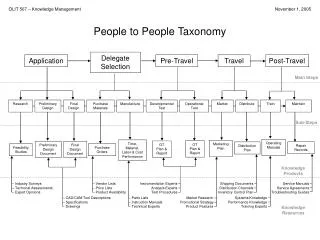
People
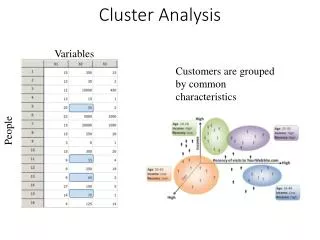
Cluster Analysis. Variables. Customers are grouped by common characteristics. People. K-means. Minimize squared error, the distance between points labeled to be in a cluster and a point designated as the center of that cluster. K-means Clustering.

People
E N D
Presentation Transcript
Cluster Analysis Variables Customers are grouped by common characteristics People
K-means • Minimize squared error, the distance between points labeled to be in a cluster and a point designated as the center of that cluster.
K-means Clustering - Each cluster is represented by the center of the cluster. The algorithm steps: Step 1: Choose the number of clusters, k. Step 2: Randomly generate k clusters and determine the cluster centers, or directly generate k random points as cluster centers. Step 3: Assign each point to the nearest cluster center. Step 4: Recompute the new cluster centers. Step 5: Repeat the two previous steps until some convergence criterion is met (usually that the assignment hasn't changed).
k3 k1 k2 Step 1: Choose the number of clusters, k. Algorithm: k-means, Distance Metric: Euclidean Distance 5 4 3 2 1 0 0 1 2 3 4 5
k1 k2 k3 Step 2: Randomly generate k clusters and determine the cluster centers, or directly generate k random points as cluster centers. 5 4 3 2 1 0 0 1 2 3 4 5
k1 k2 k3 Step 3: Assign each point to the nearest cluster center. 5 4 3 2 1 0 0 1 2 3 4 5
k1 k2 k3 Step 4: Recompute the new cluster centers. 5 4 3 2 1 0 0 1 2 3 4 5
k1 k2 k3 Step 5: Repeat the two previous steps until some convergence criterion is met
Advantages/Disadvantages: K-means Advantages: • Relatively efficient Disadvantages: • Unable to handle noisy data and outliers • Very sensitive with respect to initial choice of clusters • Need to specify number of clusters in advance • Applicable only when mean is defined – what about categorical data?