Call Routing
Explore advanced vector-based call routing techniques using classifiers, boosting, and discriminative training. Improve ASR results and out-of-domain detection for efficient call routing. Understand the caller's request and take appropriate actions.


Call Routing
E N D
Presentation Transcript
Call Routing Shih-Hsiang Lin 2007/08/02
References • Classifiers • Vector-based • [CL 1999] Vector Based Natural Language Call Routing, Bell Labs • [ACL’98] Dialogue Management in Vector-Based Call Routing, Bell Labs • [ICSLP 2002] Natural Language Call Routing A robust, Self-Organizing Approaches, Bell Labs • Maximum Entropy Classifier • [ICASSP 2003] Speech Utterance Classification, Microsoft • [ICASSP 2006] Speech Utterance Classification Model Training Without Manual Transcriptions, Microsoft • Multinomial Model for Keywords • [ICASSP 1999] Automatic Topic Identification for Two-Level Call Routing, BBN • [ICASSP 2002] Unsupervised Training Techniques for Natural Language Call Routing, BBN • [ICSLP 2002] Speech-Enable Natural Language Call Routing: BBN Call Director, BBN • Boosting • [ML 2000] BoosTexter: A Boosting-based System for Text Categorization, AT&T • [ASRU 2001] BoosTexter for Text Categorization in Spoken Language Dialogue, AT&T • Phonotactic Models • [NACCL 2003] Effective Utterance Classification with Unsupervised Phonotactic models, AT&T Labs • [SC 2005] Task Independent Call Routing , East Anglia Univ.
References (cont.) • N-gram Classifier • [Eurospeech 2003] Discriminative Training of N-gram Classifiers for Speech and Text Routing.pdf, Microsoft • Multiple Classifier • [ASRU 2001] Natural Language Call Routing: Towards Combination and Boosting of Classifiers, Bell Labs • [Eurospeech 2005] Exploiting Unlabeled Data using Multiple Classifiers for Improved Natural Language Call-Routing, IBM • Improves the Classifier • Discriminative Term Selection • [ICSLP 2002] Improving Latent Semantic Indexing based Classifier with Information Gain, Avaya Lab • Discriminative Training • [ICASSP 2001] Simplifying Design Specification for Automatic Training of Robust Natural Language Call Router, Bell Lab • [ICSLP 2002] Discriminative Training for Call Classification and Routing, Bell Lab • [SAP 2003]Discriminative Training of Natural Routers, Bell Lab • [ICASSP 2007] A Discriminative Training Framework Using N-Best Speech Recognition Transcriptions and Scores for Spoken Utterance Classification, Microsoft • Others • [ICASSP 2004] Extending Boosting for Call Classification Using Word Confusion Networks, AT&T
References (cont.) • Improves the ASR results • [ICASSP 2007] Improving Automatic Call Classification using Machine Translation, IBM • [ICCC 2004] Improved LSI-based Natural Language Call Routing using Speech Recognition Confidence Scores, Ohio Univ. • Out-of-domain (OOD) Detection • [ICASSP 2004] Out-of-domain Detection Based on Confidence Measures From Multiple Topic Classification, ATR • [ASLP 2007] Out-of-domain Utterance Detection Using Classification Confidences of Multiple Topics, ATR • Other • [SIGCHI 2002] A Comparative Study of Speech in The Call Center: Natural Language Call Routing vs Touch-Tone Menus, BBN
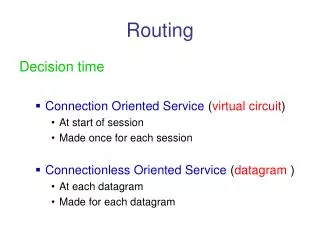
Call Routing • Callers, having dealt with many IVRs (Interactive Voice Response systems ) that are difficult to use, dislike touchtone IVRs and seek agent assistance at the first opportunity • Because of high agent costs, call center managers continue to seek automation with IVRs • How may I help you ?? • The goal of call-routing is to understand the caller’s request and take the appropriate action • Routed to the appropriate destination • Transferred to a human operator • Asked a disambiguation question • Typically, natural language call routing requires two statistical models • The first performs speech recognition to transcribe what the caller says • The second is the Action Classification (AC) that takes the spoken utterances and predicts the correct action to fulfill caller’s request • Vector-Space Model, Naïve Bayes Classifier (NBC), Support Vector Machines (SVM), Boosting, Maximum Entropy (ME), etc.
Vector-Based Call Routing (cont.) • Using vector-based information retrieval techniques • Each of destination is represented as a vector in n-dimensional space • Given a query, a query vector is computed and compared to the existing document vectors • Those destinations whose vectors are similar to the query vector are returned • Three issues must be addressed • Determine the vector representation for each destination • Determine how a caller request will be mapped to the same vector space for comparison with the destination vectors • Decide how the similarity between the request vector and each destination vector will be measured
Vector-Based Call Routing (cont.) Routing Module
Vector-Based Call Routing (cont.) • Morphological Filtering and Stop Word Filtering • Concerned with the semantics of the words present in a document • Morphological processor • Extract the root form of each word in the corpus • Reduce singulars, plurals, gerunds and various verb forms to their root forms • e.g. {service, services, servicing} service • Stop Word Filtering • Ignore list • consists of noise words which are common in spontaneous speech and can be removed without altering the meaning of an utterance • e.g. um, uh and ah • Stop list • enumerates words that are ubiquitous and therefore do not contribute to discriminating between destinations • e.g. the, be, for and morning
Vector-Based Call Routing (cont.) • Term Extraction • In order to capture word co-occurrence, n-gram terms are extracted from the filtered texts • A list of n-gram terms and their counts are generated • When an n-gram term is extracted all of the lower order k-grams where are also extracted • Thresholds are then applied to the n-gram counts to select as salient term • Unigram : 2, bigrams: 3, trigrams: 3 • Resulted in 62 trigrams, 275 bigrams and 420 unigram • Term-Document Matrix Construction • Construct an mxn term-document frequency matrix A • The matrix A is normalized so that each term vector is of unit length • Using inverse-document frequency weighting scheme to emphasis term which only occurs in a few documents d(t) is the number of documents containing the term t
Vector-Based Call Routing (cont.) • Singular Value Decomposition and Vector Representation • To provide a uniform representation of term and document vectors and to reduce the dimensionality of the document vectors • Representing documents by row vectors in allows us to make comparisons between documents as well as between documents • For query vector , the representing vector is obtained by multiplying • Candidate Destination Selection • Using cosine similarity measure However although the raw vector cosine scores give some indication of the closeness of a request to a destination, but the absolute value of closeness does not translate directly into the likelihood for correct routing
Vector-Based Call Routing (cont.) • A sigmoid function is applied in this paper • From each call in the training data, for each destination, {cosine value, routing value} pair is used for finding the parameters of sigmoid function • Raw cosine scores: 92.2% Sigmoid confidence fitting: 93.5% • Once we have obtained a confidence value for each destination • Final step in the routing process is to compare the confidence values to a predetermined threshold • Return those destinations whose confidence values are greater than the threshold as candidate destinations
Vector-Based Call Routing (cont.) • Experimental Evaluation • 389 request and 23 destinations Performance on Transcriptions Performance on ASR outputs Vector-based Call Routing yields about 96.7% and 93% classification accuracy for manual transcriptions and ASR outputs, respectively
Maximum Entropy Classifier • Most speech utterance classification systems adopt a data-driven statistical learning approach • Requires manual transcriptions of speech utterances and annotations of classification destinations for the utterances • Time-consuming and expensive, and have become a bottleneck for the rapid development of spoken language applications • In this paper, they investigate classification model training based on automatic word transcriptions • Maximum Entropy Classifier
Maximum Entropy Classifier (cont.) • A straightforward way to train a ME classifier without manual transcriptions is to use ASR transcriptions • Because in-domain transcriptions are no available for language model (LM) training • The mismatch of language models results in an over 50% increase in classification error rate • Language Model Adaptation is needed • One way to adapt the language model involves a small amount of transcribed data • Interpolated with the background language model • However, this is a supervised adaptation and transcribed data is needed • An alternative is self-adaptation, or unsupervised adaptation • The speech utterance are first recognized with background LM • The recognized strings are then used to train a domain specific LM • Then, iteratively, the newly interpolated model is use to perform recognition again
Maximum Entropy Classifier (cont.) • One problem with the self-adaptation mechanism is that the recognition errors are fed back to new language model • e.g. “a b c” is misrecognized “a b d” in the first iteration, then it is almost hopeless to recover from this error in the subsequent iterations • In this paper, two-fold cross-validation unsupervised sel-adaptations mechanism is used • The training utterances are randomly partitioned into two disjoint sets A and B • The background LM is used to recognize utterances in A • It is then adapted with the recognized text for the recognition of the utterance in B • The text recognized from B is in turn used to adapt the background LM to recognized again the utterances in A • This process iterates until there is no improvement of classification accuracy on the development set
Maximum Entropy Classifier (cont.) • Experimental Evaluation ATIS Supervised adaptation
Maximum Entropy Classifier (cont.) • It is interesting to note that the WERs of the training set are about 30% higher than the corresponding WERs of the test set • This indicates that improvement can be achieved if we correctly address the error feedback problem in the self-adaptation method Unsupervised adaptation This self-adaptation mechanism reduces the CER by 26% over the baseline, and it outperforms the approach of LM adaptation with partially transcribed in-domain data The two-fold cross validation reduces the error feedback problem in LM self adaptation
BBN Call Director • BBN call director uses a statistical language model for speech recognition and a statistical topic identification (TID) system to identify the topic from the call • Uses a multinomial model for keywords • Incorporates two difference classifier • Bayesian classifier • Log Odds classifier
BBN Call Director (cont.) • A caller’s request can be defined as a sequence or word r = {ri}, where each word . is a keyword set of words and includes a non-keyword symbol. as the set of all system topics • The PDF of the caller’s request conditioned on topics can be modeled as a multinomial distribution • The parameters of the multinomial model are trained using ML estimation: number of times word wi occurs in r the number of unique words that occur in topic tj
BBN Call Director (cont.) • Design of classifier • Bayesian Classifier: maximizing the posterior probability • The TID system returns a list of topics which have the probability above the rejection threshold • Log Odds Classifier: maximizing the posterior topic log odds Misrouted calls: 28%
Naïve Bayes Classifier • The estimated probability of word in the document given the class the document belong to is as follows • The class prior probability is computed similarly but without smoothing • The probability of a class model given a document is calculated by The class that achieved the highest posterior probability for the test document is selected
Naïve Bayes Classifier (cont.) • Experimental Evaluation Technical assistances • The results show that as labeled data increases • performance improves
Boosting • Boosting is an iterative method for improving the accuracy of any given learning algorithm • The premise of Boosting is to produce a very accurate prediction rule by combing moderately inaccurate (week) rules • The algorithm operates by learning a weak rule at each iteration so as to minimize the training error rate
Boosting (cont.) Normalizedfactor • The output of the final classifier is given below
Boosting (cont.) “Base” refers to AC accuracy obtained on the test data using only limited labeled data “Rover” refers to AC accuracy results on the test data where classifier are trained using the augmented training material “Bound” refers to lumping labeled data and unlabeled data with their true labels Combining the classifiers improved action classification accuracy compared to single classifier performance consistently across a wide range of labeled data amounts
BoosTexter • The basic idea of boosting is to build a highly accurate classifier by combining many “weak” or “simple” base classifiers • Each one of which may only be moderately accurate • The collection of base classifiers is constructed in rounds • On each round t, the base learner is used to generate a base classifier ht • Besides supplying the base learner with training data, the boosting algorithm also provides a set of nonnegative weights wt over the training examples • The weights encode how important it is that ht correctly classify each training example • to force the base learner to focus on the “hardest” examples • In this paper, they use confidence-rated classifiers • Classifier h output a real number rather than output -1 or +1
BoosTexter (cont.) • The real-valued predictions of the final classifier can be converted into probabilities by passing them through a logistic function • we can regard the quantity as an estimate of the probability that x belongs to class +1 • For instance, the base classifier might be: “If the word ‘yes’ occurs in the utterance, then predict +1.731, else predict -2.171.”
BoosTexter (cont.) • Evaluation Results
Phonotactic Models • A major bottleneck in building data-driven speech processing applications is the need to manually transcribe training utterance into words • This paper proposed a unsupervised methods for utterance classification
Phonotactic Models (cont.) • Training procedure is divided into two phases • First, train a phone n-gram model • Second, train a classification model mapping phone strings to actions • Using BoosTexter Classifier Iterative procedure times repeat
Phonotactic Models (cont.) • Experimental Evaluations • experimental conditions • The suffixes (M and H) in the condition names refer to whether the training phases uses inputs produced by machine (M) or human (H) live English product information order transactions Task 1 Task 2 Task 3 Phone-based method with short “phrasal” contexts has classification accuracy that is so close to that provided by the longer phrasal contexts of trigram word recognition and word-string classification.
Phonotactic Models (cont.) • The effectiveness of unsupervised training is shown as follows Task 1 Task 2 Task 3 For all three tasks, unsupervised recognition model training improves both recognition and classification accuracy compared with a simple phone loop.
N-gram Classifier • One-pass Utterance Classification • Utterance A is assigned a class concurrently with speech decoding that finds the word string • In a one-pass scenario one builds a recognition network that stacks each of language models in parallel • Two-pass Utterance Classification
Beta Classifier • Each topic is represented by a word vocabulary and for each word we compute its probability in the topic and it weight • A query is routed to the destination j with the highest similarity measure • Parameters and are estimated on a development corpus to boost the accuracy • The term βj is the weight assigned to topic Tj weight assign to word wk the number of words in the k-th topic-vocabulary
Relevance Feedback Technique • It is hard for an average user to formulate a “good query” • Aids for good query formulation should be provided to users Assume represent the original user call the topic number the vector representing the i-th topic the set of relevant topics Hence, the classifier starts by computing the R best topics of the user-query Builds the set and then reformulates the query as follow and denote interpolation parameter represents how far the new vector should be pushed toward the relevant docs represents how far it should be pushed away from the non-relevant ones
Constrained Minimization Technique • Suppose we have two uncorrelated classifier C1 and C2 which predict the topic t1 and t2 respectively for query q • When both classifier agree (t1 = t2), the topic result is the same as each of the classifier • When they disagree, a third classifier is invoked as a arbiter • The third classifier may be explicitly trained on disagreements of the first two using minimum error training • And can also make a choice only on a subset of topics • This subset may be computed according to the N-best topics proposed by each of the first two classifiers or according to a confusion measure
Experimental Results • Experimental Evaluation USAA banking OASIS BT DT: Discriminative Training ARF: Automatic Relevance Feedback • The better the initial classifier, the less the improvement from • boosting • The reformulation of the user request can help the classifier
Experimental Results (cont.) LI: Linear Interpolation CM_D: according to confusion measure CM_N: according to N-best topics (N=2) • Experiments show that the combination between these two • classifier is a good way to improve the performance • The performance in BT corpus did not give a significant • improvement. The reason disagreement between the first two • classifier is quite high on the entire test set, about 65%
Discriminative Term Selection • In the previous LSA (or LSI) based approach, terms are selected based on their occurrence statistics in the training data • Terms selected or discarded in this process may or may not be salient • Therefore, term selection is an active research area • A subset of terms can be chosen based on the value of importance factors • e.g. Information Gain (IG), Mutual Information (MI), -test … etc • In this paper, the discriminative power of the term is measured by the average entropy variations on the topics when the term is present or absent • Each term is assigned a numeric value that indicated the importance of the term
Discriminative Term Selection (cont.) • The IG score of a term ti is calculated according to the following formulas The right side of Formula (1) can be calculated as follows
Discriminative Term Selection (cont.) • Experimental Evaluation • Three sets of comparative experiments were performed • Baseline, Term count approach, IG approach Enterprise call centre The experimental results indicated that the proposed approach has the performance advantages in all threes conditions over the other two approaches
Improving Automatic Call Classification using Machine Translation • Utilize the translation model in statistical machine translation (SMT) • To capture the relation between truth and the ASR transcribed text • Model is trained using the human transcribed text and the ASR transcribed text • The ASR transcribed text is sanitized before feeding the classifier • The sanitization process is thought of as a translation process • SOURCE: ASR output TARGET: Human transcribed text • The IBM statistical Translation models are based on the source-channel paradigm of communication theory Noisy Communication Channel noisy sentence n (target language) clean sentence c (source language) translation model probability language model probability
Improving Automatic Call Classification using Machine Translation (cont.) • This paper used IBM Model 2 to learn the relationship between the clean utterances and the ASR transcribed text • For a clean sentence c of length l, choose the length m of the noisy sentence from distribution • For each position j=1,2,…,m in the noisy sentence, choose a position aj in the clean sentence from a distribution • For each word at j=1,2,…,m in the noisy sentence, choose a word cjfrom the manual transcription according to the distribution • The probability of generating a clean sentence c=c1c2c3…cmgiven a noisy input n=n1n2n3…nl is given by Length model Alignment model Lexicon model
Improving Automatic Call Classification using Machine Translation (cont.)
Improving Automatic Call Classification using Machine Translation (cont.)