Download

1 / 41
410 likes | 561 Vues
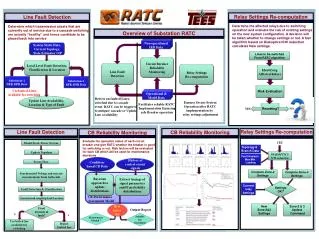
The Conjunction of Process and Spectral Data for Enhanced Fault Detection. Elaine Martin Centre for Process Analytics and Control Technology University of Newcastle, England www.ncl.ac.uk/cpact/. Motivation.

E N D
The Conjunction of Process and Spectral Data for Enhanced Fault Detection Elaine Martin Centre for Process Analytics and Control Technology University of Newcastle, England www.ncl.ac.uk/cpact/
Motivation • It is conjectured that there may be factors relating specifically to a process that cannot be identified from the spectroscopic measurements that could be described by the process data or vice versa. • Consequently one way to enhancing prediction accuracy and process performance and fault detection is through the integration of process and spectral data. • The aim of the subsequent studies was to investigate the combined power of spectral and process data.
Overview • Process Modelling • Fermentation Process • Spectral Data • Spectral and Process Data • Process Monitoring and Fault Detection • Polymer-resin Manufacturing • Process Data • Process and Spectral Data
Challenges in the Monitoring of Fermentation Processes • Fermentation is a process in which micro-organisms convert chemical species to products of higher value. • On-line information relating to the progression of the process is not easily attained. • Near Infrared and Mid Infrared spectroscopy have been applied for the monitoring of fermentation processes. • The successful implementation of these spectroscopic approaches necessitates the application of appropriate multivariate data analysis techniques, such as partial least squares (PLS).
Experimental Data Set • The industrial pilot-plant scale Streptomyces fermentation process involves two stages: • Seed stage • Final stage • The seed stage materialises in the generation of biomass. • The starting ingredients include carbohydrate, soya protein, vegetable oil and trace elements in water. • The biomass is transferred to the final stage for the production of the desired product. • The final stage is a fed batch process lasting approximately 140hrs. • NIR measurements were collected for the final stage of the process.
Spectra Data Acquisition • The NIR spectral data were recorded using a Zeiss Corona 45
Description of the Data Set • Final stage data from 7 standard batches and 7 Design of Experiment batches form the basis of the subsequent analysis. • Data collected included on-line process data, off-line data, biochemical and NIR measurements.
Methodological Summary • Pre-processing of the spectral data set • First derivates • Splining • Segmented wavelength region selection • Global modelling – Linear PLS, Neural Network PLS, Quadratic PLS • Local modelling - Linear PLS, Neural Network PLS, Quadratic PLS • Bagging of the models • Linear partial least squares • Averaging
Data Pre-processing • The NIR data (Zeiss Corona NIR) were recorded every 15 minutes and the first derivatives were taken. • Since only ten values of titre were recorded, a spline was fitted to the data. • The splined titre values were aligned to the 550 spectral values for each batch. • The range utilised for both the spectral and quality data was 43.75 to 125 log hours.
NIR Data and First Derivatives First Derivative NIR Data
Spectral Window Selection Algorithm N Y Select training and validation batches Generate random changes to centres and widths Has the RMS on trainingdata decreased? Mean centre and take derivatives of the spectral data Apply the randomchanges to the current centres and widths Has number of iterations been exceeded and there are more models to build ? N Generate random centres and widths Build new input matrix,generate model and calculate RMS errors Y Build model ‘input’ matrix eliminating common data. Generate PLS model Calculate RMS errors Present the final bagged model
Generate random increment in centre and width Generate a new increment in centre and width and continue search Centre Centre Update the centre and width Width Width Take another step with the Centre and Width increment Step too far. The prediction error has increased. Go back to where we were. Spectral Window Selection Algorithm Has the prediction error decreased?Yes, then a step in the right direction
Benefits of the SWS Algorithm • SWS offers the opportunity to consider not only the extremes of a single wavelength and the full set but also restricts selection to multiple sub-sets of the full set. • Finds the ‘best’ possible models for the product concentration and the biochemical components. • Finds the ‘best’ wavelength range from which these models can be built.
Bagging • SWS does not provide a unique model. • To obtain a more robust model, bagging is implemented. • ‘Resample and Combine’ method or ‘bagging’ is an algorithm that helps improve the robustness of models by combining predictions from different models.
Bagging of Models • 30 models were generated by changing the initial random seed of the wavelength selection algorithm. • Bagging was applied to the 30 models: • The average value was calculated from the output of the 30 models. • A PLS model was fitted between the real and fitted values to give a weighted average.
Full data set of batch 133 0.7 0.6 0.5 Apply Global Modelling 0.4 0.3 0.2 Apply Local Modelling 0.1 0 0 100 200 300 400 500 Second half from the data set of batch 133 First half from the data set of batch 133 0.5 0.56 0.4 0.54 0.3 0.52 0.2 0.5 0.1 0.48 0 0.46 0 50 100 150 200 250 0 50 100 150 Global and Local Modelling
Local Modelling 2 critical points at 70 and 100 hourswere identified from plots of the biochemical data
Local Modelling First Time Interval Second Time Interval Third Time Interval
Local Modelling Approach • Three time regions for both the spectra and the quality variable values (titre) were selected. • Samples up to 70 log hours, i.e 175-280 sample points. • From 70 log hours to 100 log hours, i.e 280-400 sample points. • From 100 log hours up to the end of the chosen window, i.e. 400-500 sample points.
Local Modelling Approach Region 2 Region 3
Results : Time Interval 1 • The RMS of the training set for models 1, 7 and 29 is large. • The RMS of the validation data set for models 1, 7 and 29 is small. • The RMS error for PLS Bagging is smaller than the error of each individual model RMS error after PLS Bagging
Linear PLS – Region 1 (Wavelength Selection) Validation Data Set Training Data Set
Results : Time Interval 1 The wavelengths between 30 and 40 are selected most frequently.
Neural Network PLS – Region 2 (Wavelength Selection) Validation Data Set Training Data Set
Polynomial PLS – Region 3 (Wavelength Selection) Validation Data Set Training Data Set
Local Modelling : Training Data Set Local Modelling Global Modelling Global Modelling predictions Local Modelling predictions for time intervals 1, 2 and 3
Local Modelling : Validation Data Set 2nd Time Interval 1rst Time Interval 3rd Time Interval
Genetic Algorithm Results Genetic Algorithms SWS Genetic algorithms provide the possibility of selecting individual wavelengths but potentially does not predict future samples well.
GA Results – Region 2 SWS Averaging Ga’S Averaging RMS of Validation - SWS: 0.048 GAs:0.069
Genetic Algorithm Results TRAINING VALIDATION RESULTS
Summary of Results • GAs produced slightly better predictions for the training data set resulting in overfitting. • In the validation model, SWS combination with bagging for local modelling gave better results than the GA in combination with bagging. • Local modelling gives better results than global modelling. • SWS with bagging gives better results compared with the purported ‘one-shot wonder’ models.
Design of Experiment Data Integration of Process and Spectral Data
Conjunction of Process and Spectral Data • In the later stages of the fermentation, the error in the calibration models was observed to be greater with offsets being present. • During this time, significant changes in the fermentation broth concentrations occur. • The offset can potentially be modelled by utilising other process information such as off-gas measurements.
Data Set and Aim • The aim is to inferproduct concentration and the biochemical components from the spectral data. • Working on the off-line, biochemical and NIR data for the design of experiment batches. • Changing conditions in experimental design: • Temperature (°C) • pH • Sugar feed (gh-1) • Oil feed (%)
MODEL + Spectral Σ Calibration spectral residuals - Biochemical Concentration MODEL + Process Data Σ Innovations - Calibration Spectral Residuals Biochemical Concentration Predictions by Spectra Σ Final Product Concentrations Residuals Prediction by Process Data Conjunction of Process and Spectral Data First Step: Calculation of the calibration spectral residuals. Second Step: Modelling of the calibration spectral residuals from the process data and the generation of the innovations. Final Step: Prediction of the product concentration
Conjunction of Process and Spectral Data CER Temperature pH Time Series Plot Time Series Plot 2 CER 5 pH 200 400 600 800 1000 1200 1400 1600 200 400 600 800 1000 1200 1400 1600 CO2 Total OUR Time Series Plot Time Series Plot 9 OUR 3 CO2 Total 5 variables were considered to be the most important for the prediction of product concentration 200 400 600 800 1000 1200 1400 1600 200 400 600 800 1000 1200 1400 1600
Predicted train values Residuals for training data set Predicted valid values 1.4 0.7 0.2 0.15 1.2 0.6 0.1 1 0.5 0.05 0.8 0.4 0 0.6 -0.05 0.3 -0.1 0.4 0.2 -0.15 0.2 0.1 -0.2 0 0 500 1000 1500 0 -0.25 50 100 150 200 250 300 350 0 0 500 1000 1500 Conjunction of Process and Spectral Data Predictions Residuals
Real values, Predicted values and Final predicted values for valid 0.6 0.5 0.4 0.3 0.2 0.1 0 -0.1 0 50 100 150 200 250 300 350 Conjunction of Process and Spectral Data Final predictions of the product New residuals • The off-set is reduced • The residuals exhibit less structure and reflect noise
Conclusions • A Spectral Window Selection (SWS) algorithm has been proposed to select a window of wave numbers. • Multiple models are ‘bagged’ to produce a more robust model. • SWS produces better results than when the complete wavelength region is included. • Process data was combined with spectral data to eliminate offsets. • The wavelength selection-bagging approach in combination with the process data is now under investigation. • The results to date are promising.