Download

1 / 75
770 likes | 1.03k Vues
Transcription Regulation Transcription Factor Motif Finding. Xiaole Shirley Liu STAT115, STAT215, BIO298, BIST520. Outline. Biology of transcription regulation and challenges of computational motif finding Scan for known TF motif sites TRASFAC and JASPAR, Sequence Logo De novo method

E N D
Transcription RegulationTranscription Factor Motif Finding Xiaole Shirley Liu STAT115, STAT215, BIO298, BIST520
Outline • Biology of transcription regulation and challenges of computational motif finding • Scan for known TF motif sites • TRASFAC and JASPAR, Sequence Logo • De novo method • Regular expression enumeration: w-mer enumerate • Position weight matrix update: EM and Gibbs • Motif finding in different organisms • Motif clusters and conservation
Restaurant Dinner Home Lunch Certain recipes used to make certain dishes Imagine a Chef
Adult Liver Infant Skin Glucose, Oxygen, Amino Acid Fat, Alcohol Nicotine Certain genes expressed to make certain proteins Healthy Skin Cell State Disease Liver Cell State Each Cell Is Like a Chef
Understanding a Genome Get the complete sequence (encoded cook book) Observe gene expressions at different cell states (meals prepared at different situations) Decode gene regulation (decode the book, understand the rules)
Coding region 2% What is to be made Milk->Yogurt Egg->Omelet Fish->Sushi Flour->Cake Beef->Burger Information in DNA ATTTACCGATGGCTGCACTATGCCCTATCGATCGACCTCTC ATTTACCACATCGCATCACAGTTCAGGACTAGACACGGACG GCCTCGATTGACGGTGGTACAGTTCAATGACAACCTGACTA TCTCGTTAGGACCCATGCGTACGACCCGTTTAAATCGAGAG CGCTAGCCCGTCATCGATCTTGTTCGAATCGCGAATTGCCT
Morning Morning Butter Japanese Restaurant 5 Oz Butter 9 Oz Information in DNA Non-coding region 98% Regulation: When, Where, Amount, Other Conditions, etc ATTTACCGATGGCTGCACTATGCCCTATCGATCGACCTCTC ATTTACCACATCGCATCACTACGACGGACTAGACACGGACG GCCTCGATTGACGGTGGTACAGTTCAATGACAACCTGACTA TCTCGTTAGGACCCATGCGTACGACCCGTTTAAATCGAGAG CGCTAGGTCATCCCAGATCTTGTTCGAATCGCGAATTGCCT Coding region 2% Milk->Yogurt Egg->Omelet Fish->Sushi Flour->Cake Beef->Burger
Measure Gene Expression • Microarray or SAGE detects the expression of every gene at a certain cell state • Clustering find genes that are co-expressed (potentially share regulation)
Scrambled Egg Bacon Cereal Hash Brown Orange Juice Decode Gene Regulation Look at genes always expressed together: Upstream RegionsCo-expressed Genes GATGGCTGCACATTTACCTATGCCCTACGACCTCTCGC CACATCGCATATTTACCACCAGTTCAGACACGGACGGC GCCTCGATTTACCGTGGTACAGTTCAAACCTGACTAAA TCTCGTTAGGACCATATTTACCACCCACATCGAGAGCG CGCTAGCCATTTACCGATCTTGTTCGAGAATTGCCTAT STAT115, 04/01/2008
Decode Gene Regulation Look at genes always expressed together: Upstream RegionsCo-expressed Genes GATGGCTGCACATTTACCTATGCCCTACGACCTCTCGC CACATCGCATATTTACCACCAGTTCAGACACGGACGGC GCCTCGATTTACCGTGGTACAGTTCAAACCTGACTAAA TCTCGTTAGGACCATATTTACCACCCACATCGAGAGCG CGCTAGCCATTTACCGATCTTGTTCGAGAATTGCCTAT Scrambled Egg Bacon Cereal Hash Brown Orange Juice STAT115, 04/01/2008
Morning Decode Gene Regulation Look at genes always expressed together: Upstream RegionsCo-expressed Genes GATGGCTGCACATTTACCTATGCCCTACGACCTCTCGC CACATCGCATATTTACCACCAGTTCAGACACGGACGGC GCCTCGATTTACCGTGGTACAGTTCAAACCTGACTAAA TCTCGTTAGGACCATATTTACCACCCACATCGAGAGCG CGCTAGCCATTTACCGATCTTGTTCGAGAATTGCCTAT Scrambled Egg Bacon Cereal Hash Brown Orange Juice STAT115, 04/01/2008
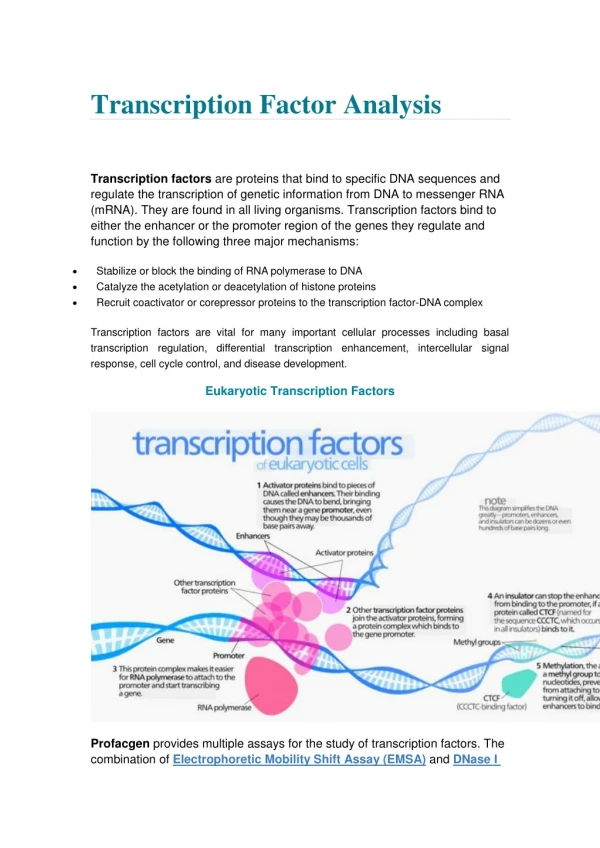
Hemoglobin Beta atttgctt ttcact gcaacct aactccagt Hemoglobin Zeta gcaacct actca Hemoglobin Alpha gcaacct Hemoglobin Gamma ccagcgccg gcaacct Transcription Factor (TF) TF Binding Motif gcaacct Biology of Transcription Regulation ...acatttgcttctgacacaactgtgttcactagcaacctca...aacagacaccATGGTGCACCTGACTCCTGAGGAGAAGTCT... ...agcaggcccaactccagtgcagctgcaacctgcccactcc...ggcagcgcacATGTCTCTGACCAAGACTGAGAGTGCCGTC... ...cgctcgcgggccggcactcttctggtccccacagactcag...gatacccaccgATGGTGCTGTCTCCTGCCGACAAGACCAA... ...gccccgccagcgccgctaccgccctgcccccgggcgagcg...gatgcgcgagtATGGTGCTGTCTCCTGCCGACAAGACCAA... Motif can only be computational discovered when there are enough cases for machine learning
Computational Motif Finding • Input data: • Upstream sequences of gene expression profile cluster • 20-800 sequences, each 300-5000 bps long • Output: enriched sequence patterns (motifs) • Ultimate goals: • Which TFs are involved and their binding motifs and effects (enhance / repress gene expression)? • Which genes are regulated by this TF, why is there disease when a TF goes wrong? • Are there binding partner / competitor for a TF?
Water Water Water Water Water Challenges: Where/what the signal The motif should be abundant GAAATATGCACATTTACCTATGCCCTACGACCTCTCGC CACATCGCATATTTACCACCAAATAAGACACGGACGGC GCCTCGAAATAGCCATTTACCGTTCAAACCTGACTAAA TCTCGTATTTACCATATTAAATACCCACATCGAGAGCG CGCTAGCAAATATACGATTTACCTCGAGAATTGCCTAT
Coconut Coconut Coconut Coconut Coconut Challenges: Where/what the signal The motif should be abundant And Abundant with significance GAAATATGCACATTTACCTATGCCCTACGACCTCTCGC CACATCGCATATTTACCACCAAATAAGACACGGACGGC GCCTCGAAATAGCCATTTACCGTTCAAACCTGACTAAA TCTCGTATTTACCATATTAAATACCCACATCGAGAGCG CGCTAGCAAATATACGATTTACCTCGAGAATTGCCTAT
||||||||||||||||||||||||||||| GTGTAGCGTACCATTTATGGTCAAGTCTG ||||||||||||||||||||||||||||| AGAGTCCATTTAGTCAGTATGATGGGTGT Challenges: Double stranded DNA Motif appears in both strands GATGGCTGCACATTTACCTATGCCCTACGACCTCTCGC CACATCGCATGGTAAATACCAGTTCAGACACGGACGGC TCTCAGGTAAATCAGTCATACTACCCACATCGAGAGCG
Challenges: Base substitutions Sequences do not have to match the motif perfectly, base substitutions are allowed GATGGCTGCACATTTACCTATGCCCTACGACCTCTCGC CACATCGCATATGTACCACCAGTTCAGACACGGACGGC GCCTCGATTTGCCGTGGTACAGTTCAAACCTGACTAAA TCTCGTTAGGACCATATTTATCACCCACATCGAGAGCG CGCTAGCCAATTACCGATCTTGTTCGAGAATTGCCTAT
Challenges: Variable motif copies Some sequences do not have the motif Some have multiple copies of the motif GATGATGCCTCGGACGGATATGCCCTACGACCTCTCGC CACATCGCAATGCAGCAATGCGTTCAGACACGGACGGC TCATGCTAATGCCAGTCATGCTACATGCATCGAGAGCG GCCTCTAGCTAGGCCGGTGAACATCAGACCTGACTAAA CGCAATATAGCATTAGCAGACAGACGAGAATTGCCTAT
Sushi Fish Fish Fish Hand Roll Fish Fish Fish Fish Sashimi Tempura Sake Challenges: Variable motif copies Some sequences do not have the motif Some have multiple copies of the motif GATGATGCCTCGGACGGATATGCCCTACGACCTCTCGC CACATCGCAATGCAGCAATGCGTTCAGACACGGACGGC TCATGCTAATGCCAGTCATGCTACATGCATCGAGAGCG GCCTCTAGCTAGGCCGGTGAACATCAGACCTGACTAAA CGCAATATAGCATTAGCAGACAGACGAGAATTGCCTAT
Coconut Milk or palindromic patterns AATGCG GCGTAA Challenges: Two-block motifs Some motifs have two parts GACACATTTACCTATGCTGGCCCTACGACCTCTCGC CACAATTTACCACCA TGGCGTGATCTCAGACACGGACGGC GCCTCGATTTACCGTGGTATGGCTAGTTCTCAAACCTGACTAAA TCTCGTTAGATTTACCACCCATGGCCGTATCGAGAGCG CGCTAGCCATTTACCGAT TGGCGTTCTCGAGAATTGCCTAT
Scan for Known TF Motif Sites • Experimental TF sites: TRANSFAC, JASPAR • Motif representation: • Regular expression: Consensus CACAAAA binary decision Degenerate CRCAAAW IUPAC A/G A/T
Segment ATGCAGCT score = p(generate ATGCAGCT from motif matrix) p(generate ATGCAGCT from background) p0A p0T p0G p0C p0A p0G p0C p0T Scan for Known TF Motif Sites • Experimental TF sites: TRANSFAC, JASPAR • Motif representation: • Regular expression: Consensus CACAAAA binary decision Degenerate CRCAAAW • Position weight matrix (PWM): need score cutoff Motif Matrix Pos 12345678 ATGGCATG AGGGTGCG ATCGCATG TTGCCACG ATGGTATT ATTGCACG AGGGCGTT ATGACATG ATGGCATG ACTGGATG Sites
A adenosine C cytidine G guanine T thymidine U uridine R G A (purine) Y T C (pyrimidine) K G T (keto) M A C (amino) S G C (strong) W A T (weak) B C G T (not A) D A G T (not C) H A C T (not G) V A C G (not T) N A C G T (any) IUPAC for DNA
Protein Binding Microarrays • In vitro protein-DNA interactions • Better capture motifs
JASPAR • User defined cutoff to scan for a particular motif
A Word on Sequence Logo • SeqLogo consists of stacks of symbols, one stack for each position in the sequence • The overall height of the stack indicates the sequence conservation at that position • The height of symbols within the stack indicates the relative frequency of nucleic acid at that position ATGGCATG AGGGTGCG ATCGCATG TTGCCACG ATGGTATT ATTGCACG AGGGCGTT ATGACATG ATGGCATG ACTGGATG
Scan Known TF Motifs • Drawbacks: • Limited number of motifs • Limited number of sites to represent each motif • Low sensitivity and specificity • Poor description of motif • Binding site borders not clear • Binding site many mismatches • Many motifs look very similar • E.g. GC-rich motif, E-box (CACGTG)
De novo Sequence Motif Finding • Goal: look for common sequence patterns enriched in the input data (compared to the genome background) • Regular expression enumeration • Pattern driven approach • Enumerate patterns, check significance in dataset • Oligonucleotide analysis, MobyDick • Position weight matrix update • Data driven approach, use data to refine motifs • Consensus, EM & Gibbs sampling • Motif score and Markov background
Expected occurrence of w in the data pw from genome background size of sequence data Regular Expression Enumeration • Oligonucleotide Analysis: check over-representation for every w-mer: • Expected w occurrence in data • Consider genome sequence + current data size • Observed w occurrence in data • Over-represented w is potential TF binding motif Observed occurrence of win the data
MobyDick • A sequence data and a dictionary of motif words ATTTACCGATGGCTGCACTATGCCCTATCGATCGACCTCTC ATGCTTCACATCGCATCACCAGTTCAGGATAGACACGGACG GCCTCGATTGACGGTGGTACAGTTCAATGACAACCTGACTA TCTCGTTAGGACCCATGCGTACGACCCGTTTAAATCGAGAG CGCTAGCCCGTCATCGATCTTGTTCGAATCGCGAATTGCCT D = {A, C, G, T} Pw = {0.22, 0.28, 0.28, 0.22}
A C G T A AA AC AG AT C CA CC CG CT G GA GC GG GT T TA TC TG TT MobyDick • A sequence data and a dictionary of motif words • Check over-representation of every word-pair ATTTACCGATGGCTGCACTATGCCCTATCGATCGACCTCTC ATGCTTCACATCGCATCACCAGTTCAGGATAGACACGGACG GCCTCGATTGACGGTGGTACAGTTCAATGACAACCTGACTA TCTCGTTAGGACCCATGCGTACGACCCGTTTAAATCGAGAG CGCTAGCCCGTCATCGATCTTGTTCGAATCGCGAATTGCCT D = {A, C, G, T} Pw = {0.28, 0.22, 0.22, 0.28}
A C G T A AA AC AG AT C CA CC CG CT G GA GC GG GT T TA TC TG TT MobyDick • A sequence data and a dictionary of motif words • Check over-representation of every word-pair ATTTACCGATGGCTGCACTATGCCCTATCGATCGACCTCTC ATGCTTCACATCGCATCACCAGTTCAGGATAGACACGGACG GCCTCGATTGACGGTGGTACAGTTCAATGACAACCTGACTA TCTCGTTAGGACCCATGCGTACGACCCGTTTAAATCGAGAG CGCTAGCCCGTCATCGATCTTGTTCGAATCGCGAATTGCCT D = {A, C, G, T} Pw = {0.28, 0.28, 0.22, 0.22} D = {A,C,G,T,AA,GA,TA,GG} Pw = {?}
MobyDick • D = {A,C,G,T,AA,GA,TA,GG} • Seq: AAGATAA • Possible partitions: A A G A T A A pA pA pG pA pT pA pA AA G A T A A pAA pG pA pT pA pA AA GA T A A pAA pGA pT pA pA AA GA TA A pAA pGA pTA pA A A GA T AA pAA pGA pT pAA … • Assign probabilities as to maximize total probability of generating the sequence
A C G T A AA AC AG AT C CA CC CG CT G GA GC GG GT T TA TC TG TT MobyDick • A sequence data and a dictionary of motif words • Check over-representation of every word-pair • Reassign word probability and consider every new word-pair to build even longer words ATTTACCGATGGCTGCACTATGCCCTATCGATCGACCTCTC ATGCTTCACATCGCATCACCAGTTCAGGATAGACACGGACG GCCTCGATTGACGGTGGTACAGTTCAATGACAACCTGACTA TCTCGTTAGGACCCATGCGTACGACCCGTTTAAATCGAGAG CGCTAGCCCGTCATCGATCTTGTTCGAATCGCGAATTGCCT D = {A, C, G, T} Pw = {0.28, 0.28, 0.22, 0.22} D = {A,C,G,T,AA,GA,TA,GG} Pw = {?}
Regular Expression Enumeration • RE Enumeration Derivatives: • oligo-analysis, spaced dyads w1.ns.w2 • IUPAC alphabet • Markov background (later) • 2-bit encoding, fast index access • Enumerate limited RE patterns known for a TF protein structure or interaction theme • Exhaustive, guaranteed to find global optimum, and can find multiple motifs • Not as flexible with base substitutions, long list of similar good motifs, and limited with motif width
Seq1 … … Seq2 Good Motifs CACGTGC GTCAGTC CACGTTC GTCAGTC Bad Motifs CACGTGC GTCAGTC GTGACATTGGAAAT Consensus • Starting from the 1st sequence, add one sequence at a time to look for the best motifs obtained with the additional sequence
… Seq3 … Good Motifs CACGTGC GTCAGTC CACGTTC GTCAGTC CTCGTGC GACAGTC Bad Motifs CACGTGC GTCAGTC CACGTTC GTCAGTC TTCAAAGAGACTCA Consensus • Starting from the 1st sequence, add one sequence at a time to look for the best motifs obtained with the additional sequence Remaining good motifs …
Consensus • Starting from the 1st sequence, add one sequence at a time to look for the best motifs obtained with the additional sequence • G Stormo, algorithm runs very fast • Sequence order plays a big role in performance • First two sequences better contain the motif • Sites stop accumulating at the first bad sequence • Newer version allowing [0-n] is much slower
Expectation Maximization and Gibbs Sampling Model • Objects: • Seq: sequence data to search for motif • 0: non-motif (genome background) probability • : motif probability matrix parameter • : motif site locations • Problem: P(, | seq, 0) • Approach: alternately estimate • by P( | , seq, 0) • by P( | , seq, 0) • EM and Gibbs differ in the estimation methods
E step: | , seq, 0 TTGACGACTGCACGT TTGAC p1 TGACG p2 GACGA p3 ACGAC p4 CGACT p5 GACTG p6 ACTGC p7 CTGCA p8 ... P1 = likelihood ratio = P(TTGAC| ) P(TTGAC| 0) Expectation Maximization p0T p0T p0G p0A p0C = 0.3 0.3 0.2 0.3 0.2
E step: | , seq, 0 TTGACGACTGCACGT TTGAC p1 TGACG p2 GACGA p3 ACGAC p4 CGACT p5 GACTG p6 ACTGC p7 CTGCA p8 ... M step: | , seq, 0 p1 TTGAC p2 TGACG p3 GACGA p4 ACGAC ... Scale ACGT at each position, reflects weighted average of Expectation Maximization
EM Derivatives • First EM motif finder (C Lawrence) • Deterministic algorithm, guarantee local optimum • MEME (TL Bailey) • Prior probability allows 0-n site / sequence • Parallel running multiple EM with different seed • User friendly results
Gibbs Sampling • Stochastic process, although still may need multiple initializations • Sample from P( | , seq, 0) • Sample from P( | , seq, 0) • Collapsed form: • estimatedwith counts, not sampling from Dirichlet • Sample site from one seq based on sites from other seqs • Converged motif matrix and converged motif sites represent stationary distribution of a Markov Chain
Gibbs Sampler nA1 + sA nA1 + sA +nC1 + sC +nG1 + sG +nT1 + sT estimated with counts pA1 = 1 11 2 21 31 3 4 41 51 5 Initial 1 • Randomly initialize a probability matrix
1 Without 11Segment Gibbs Sampler • Take out one sequence with its sites from current motif 11 21 31 41 51
1 Without 11Segment Gibbs Sampler • Score each possible segment of this sequence Sequence 1 Segment (1-8) 21 31 41 51
Gibbs Sampler 1 Without 11Segment • Score each possible segment of this sequence Sequence 1 Segment (2-9) 21 31 41 51
Motif Matrix Pos 12345678 ATGGCATG AGGGTGCG ATCGCATG TTGCCACG ATGGTATT ATTGCACG AGGGCGTT ATGACATG ATGGCATG ACTGGATG Segment ATGCAGCT score = p(generate ATGCAGCT from motif matrix) p(generate ATGCAGCT from background) p0A p0T p0G p0C p0A p0G p0C p0T Sites Segment Score • Use current motif matrix to score a segment
Scoring Segments Motif 1 2 3 4 5 bg A 0.4 0.1 0.3 0.4 0.2 0.3 T 0.2 0.5 0.1 0.2 0.2 0.3 G 0.2 0.2 0.2 0.3 0.4 0.2 C 0.2 0.2 0.4 0.1 0.2 0.2 Ignore pseudo counts for now… Sequence: TTCCATATTAATCAGATTCCG… score TAATC … AATCA 0.4/0.3 x 0.1/0.3 x 0.1/0.3 x 0.1/0.2 x 0.2/0.3 = 0.049383 ATCAG 0.4/0.3 x 0.5/0.3 x 0.4/0.2 x 0.4/0.3 x 0.4/0.2 = 11.85185 TCAGA 0.2/0.3 x 0.2/0.3 x 0.3/0.3 x 0.3/0.2 x 0.2/0.3 = 0.444444 CAGAT …