Analyzing Continuous and Categorical IVs Simultaneously
280 likes | 390 Vues
This article explores the intricacies of Analysis of Covariance (ANCOVA) when modeling a single categorical and a single continuous independent variable (IV). It discusses the interpretation of main effects and interactions, the significance of regression coefficients, and the importance of avoiding the dichotomization of continuous variables. The piece elaborates on testing sequences, the significance of interaction terms, and how to effectively present findings using graphs. Key concepts such as ordinal vs. disordinal interactions and regions of significance in regression lines are also examined.

Analyzing Continuous and Categorical IVs Simultaneously
E N D
Presentation Transcript
Analyzing Continuous and Categorical IVs Simultaneously Analysis of Covariance
When we model a single categorical and a single continuous variable, what do the main effects look like? What do the interactions look like? What is the meaning of each of the three b weights in such models? What is the sequence of tests used to analyze such data? Why should we avoid dichotomizing continuous IVs? What is the difference between ordinal and disordinal interactions? Why do we test for regions of significance of the difference between regression lines when we have an interaction? Skill Set
Mixed IVs • Simplest example has 2 IVs • 1 IV is categorical (e.g., Male, Female) • 1 IV is continuous (e.g., MAT score) • Keats:Shelly::Byron:Harley-Davidson • DV is continuous, e.g., GPA in law school • Have used ANOVA for categorical and Regression for continuous • Both are part of GLM. Many people call mixing categorical and continuous vbls Analysis of Covariance (ANCOVA).
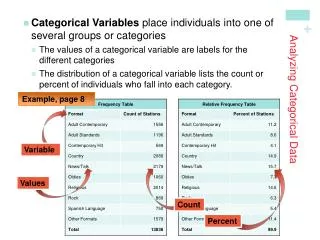
Example Data Note that there are 40 people here. Effect coding (1, -1) has been used to identify males vs. females. Doesn’t matter which is which (-1, 1) for coding purposes.
Example Data Graph What is the main story here?
Group vs. Common Regression Coefficient • Can have 1 common slope, bc. • Can have 2 group slopes, bF and bM. • Common slope is weighted average of group slopes: • Weight by SSX (here, MAT scores) for each group. Weight comes from variability in X and number of people in group.
Telling the Story With Graphs (1) Why is there nothing to tell here?
Telling the Story (2) How does the graph tell us which variable is important?
Telling the Story (3) What stories are being told in each of these graphs? When the story is obvious, the graph tells it. But we need statistical tests when the results are not obvious, and when we want to persuade others (publish).
Testing Sequence (1) • Construct vectors X, G and XG. • X is continuous • G is group (categorical) • XG is the product of the two. Just mult. • Intercept for common group is a. Note three b weights. First tells difference in groups. Second is common slope. Third is interaction (difference in group slopes). Two common terms, two difference terms.
Testing Sequence (2) • Estimate 3 slopes (and intercept). • Examine R2 for model. If n.s., no story; quit. If R2 sig and large enough: • Examine b3. If sig, there is an interaction. If sig, estimate separate regressions for different groups. • If b3 is not sig, re-estimate model without XG. Examine b1 and b2.
Is b1significant? (G, categorical) Is b2 significant? (X, cont) Yes No Yes Parallel slopes, different intercepts Identical regressions No Mean diffs only; slopes are zero Only possible with severe confounding; ambiguous story. Testing Sequence (3) The significance of the b weights tells the importance of the variables.
R2 = .44; p < .05 Y' = -.0389+.75G+.0673X-.0146GX Term Estimate SE t G (b1; Sex) .75 .6856 1.0567 X (b2; MAT) .0673 .0125 4.9786* GX (b3; Int) -.0146 .0135 -1.0831 Test Illustration (1) Step 1. R2 is large & sig. Step 2. Slope for interaction (b3) is N.S. (low power test) Step 3. Drop GX and re-estimate.
R2 = .42; p < .05 Y' = .1154+.0045G+.0687X Term Estimate SE t G (b1; Sex) .0045 .0833 .1365 X (b2; MAT) .0687 .0135 5.0937* Test Illustration (2) Step 4. Examine slopes (b weights). The only significant slope is for MAT. Conclusion: Identical regressions for Males and Females. The slight difference in lines is due to sampling error.
Second Illustration (1) Suppose our data look like these. What story do you think they tell?
R2 = .72; p < .05 R2 = .72; p < .05 Y' = -11.54+.8268G+.0643X-.0117GX Y' = -.1805+.2346G+.0655X Term Term Estimate Estimate SE SE t t p p G (b1; Sex) G (b1; Sex) .2346 .8268 .0320 .6627 1.2476 7.34 .0001 .22 X (b2; MAT) X (b2; MAT) .0643 .0655 .0130 .0131 5.05 4.2947 .0001 .0001 GX (b3; Int) -.0117 .0131 -.8945 .3770 Second Illustration (2) • Is there any story to tell? • Is there an interaction? What is the story? Does it agree with the graph?
More Complex Designs • With more complex designs, logic and sequence of tests remain the same. • Categorical vbls may have more than 2 levels • We may have several continuous IVs • If multiple categories, create multiple (G-1) interaction terms. If multiple Xs, create products for each. Test the terms as a block using hierarchical regression:
Categorizing Continuous IVs • The median split (e.g., personality, stress, BEM sex-role scales). • Don’t do this because: • Loss of power and information – treat IQs of 100 and 140 as identical. • Loss of replication (median changes by sample) • Arbitrary value of split - “high stress” group may not be very stressed • Some throw out middle people – also a problem because of range enhancement bias.
No interaction Ordinal Interaction Disordinal Interaction Interactions • Some research is aimed squarely at interactions, e.g., Aptitude Treatment Interaction (ATI) research. Learning styles, etc. • Types of Interactions: Implications?
Regions of Significance With a disordinal interaction, there must be a place where the treatments are equal (where the lines cross). Some places on X give equivalent effects. Other places show a benefit to one treatment or the other. The crossover is found by (a1-a2)/(b2-b1) or (4-1.5)/(.8-.3) = 2.5/.5 =5, just where it appears to be on the graph.
Simultaneous Regions of Significance F is the tabled value. N is n1+n2 = total people.
Disordinal Example (1) N=40. X = learning style questionnaire score. G = method of instruction. DV is in-class test score. Hypothetical experiment in teaching Research Methods. Learning style – high scores indicate preference for spoken instruction. Two instruction methods – graphics intensive and spoken intensive.
R Source Y (Test) Df X (Learn Style) SS G (Lect v. tutor) MS GX (Int) F Model 3 8035.69 2678.56 119.53 Y 1 Error 36 806.70 22.41 X .22 1 C Total 39 8842.40 G -.09 .03 1 R2=.91 GX .35 .02 .88 1 Variable Estimate SE t p M 73.8 27.78 0 .43 Int 67.09 SD 15.06 15.14 1.01 31.94 G -26.99 1.58 -17.09 .0001 X .227 .05 4.54 .0001 GX .917 .05 18.33 .0001 Disordinal Example (2)
n1=20 Source Y Df X SS G=1 G=1 Y Model 1 1 R 5805.09 X Error .95 18 1 651.71 M C Total 72.4 19 28.2 6456.80 R2 = .90 SD 18.43 15.26 Variable Estimate SE t p Int 40.10 2.88 13.9 .0001 X 1.15 .09 12.66 .0001 Disordinal Example (3) Group 1 data
n2=20 Source Y df X SS G=-1 G=-1 Y Model 1 1 R 2152.21 Error X -.97 18 1 154.99 C Total M 75.2 19 27.35 2307.20 R2 = .93 SD 11.02 15.41 Variable Estimate SE t P Int 94.09 1.36 69.03 .0001 X -.69 .04 -15.81 .0001 Disordinal Example (4) Group 2 data
N=40 n1=20 n2=20 Group1 = 1 Group2 = -1 F.05(2,36)=3.26 SSres(tot) = 806.70 SSres(1) = 651.71 SSres(2) = 154.99 Note: SSres(tot) = SSres(1) + + SSres(2) =4424.48 SD=15.26, SS =SD2*(N-1) =4511.89 SD=15.41, SS=15.41*15.41*19 =28.2 From corrs =27.35 From corrs a1=40.10 b1=1.15 a2=94.09 b2=-.69 Disordinal Example (5) Therefore, the regression will all terms included is: Y'=67.09 - 26.99G + .23X + .92GX The regression for the 1 group is: Y'=40.1 + 1.15X The regression for the -1 group is: Y'= 94.09 - .69X. To find the crossover point, we find (a1-a2)/(b2-b1) which, in our case is (94.09-40.1)/(1.15+.69) = 29.34.
Lower 27.26 Middle 29.34 Upper 31.48 Disordinal Example (6) Therefore, our estimates are:
Disordinal Example (7) N.S. Region