Towards Semantics for IR
860 likes | 1.05k Vues
Towards Semantics for IR. Eugene Agichtein Emory University. Acknowledgements A bunch of slides in this talk are adapted from lots of people, including Chris Manning, ChengXiang Zhai, James Allan, Ray Mooney, and Jimmy Lin. Who is this guy?.

Towards Semantics for IR
E N D
Presentation Transcript
Towards Semantics for IR Eugene Agichtein Emory University AcknowledgementsA bunch of slides in this talk are adapted from lots of people, including Chris Manning, ChengXiang Zhai, James Allan, Ray Mooney, and Jimmy Lin. CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Who is this guy? Sept 2006-: Assistant Professor in the Math & CS department at Emory. 2004 to 2006: Postdoc in the Text Mining, Search, and Navigation group at Microsoft Research, Redmond. 2004: Ph.D. in Computer Science from Columbia University: dissertation on extracting structured relations from large unstructured text databases 1998: B.S. in Engineering from The Cooper Union. Research interests: accessing, discovering, and managing information in unstructured (text) data, with current emphasis on developing robust and scalabletext mining techniques for the biology and health domains. CS 584: Information Retrieval. Math & Computer Science Department, Emory University
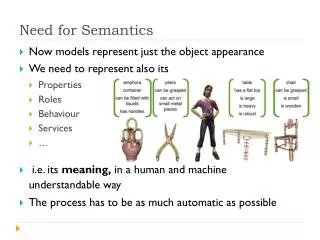
Outline • Text Information Retrieval: 10-minute overview • Problems with lexical retrieval • Synonymy, Polysemy, Ambiguity • A partial solution: synonym lookup • Towards concept retrieval • LSI • Language Models for IR • PLSI • Towards real semantic search • Entities, Relations, Facts, Events in Text (my research area) CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Document corpus Query String 1. Doc1 2. Doc2 3. Doc3 . . Ranked Documents Information Retrieval From Text IR System CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Resource Query Ranked List Documents query reformulation, vocabulary learning, relevance feedback Documents source reselection Was that the whole story in IR? Source Selection Query Formulation Search Selection Examination Delivery CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Supporting the Search Process Source Selection Resource Query Formulation Query Search Ranked List Selection Indexing Index Documents Examination Acquisition Documents Collection Delivery CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Example: Query • Which plays of Shakespeare contain the words BrutusANDCaesar but NOTCalpurnia? • One could grep all of Shakespeare’s plays for Brutus and Caesar, then strip out lines containing Calpurnia? • Slow (for large corpora) • NOTCalpurnia requires egrep • But other operations (e.g., find the word Romans nearcountrymen , or top-K scenes “most about” ) not feasible CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Term-document incidence 1 if play contains word, 0 otherwise BrutusANDCaesar but NOTCalpurnia CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Incidence vectors • So we have a 0/1 vector for each term. • Boolean model: • To answer query: take the vectors for Brutus, Caesar and Calpurnia (complemented) bitwise AND. • 110100 AND 110111 AND 101111 = 100100 • Vector-space model: • Compute query-document similarity as dot product/cosine between query and document vector • Rank by similarity CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Answers to query • Antony and Cleopatra, Act III, Scene ii • Agrippa [Aside to DOMITIUS ENOBARBUS]: Why, Enobarbus, • When Antony found Julius Caesar dead, • He cried almost to roaring; and he wept • When at Philippi he found Brutus slain. • Hamlet, Act III, Scene ii • Lord Polonius: I did enact Julius Caesar I was killed i' the • Capitol; Brutus killed me. CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Modern Search Engines in 1 Minute index angina 5 • Crawl Time: • “Inverted List”: terms doc IDs • “Content chunks” (doc copies) • Query Time: • Lookup query terms in IL “filter set” • Get content chunks for doc IDs • Rank documents using hundreds offeatures (e.g., term weights, web topology, proximity, position) • Retrieve Top K documents for query ( K < 100 << |filter set|) treatment 4 Content chunks CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Outline • Text Information Retrieval: 10-minute overview • Problems with lexical retrieval • Synonymy, Polysemy, Ambiguity • A partial solution: synonym lookup • Towards concept retrieval • LSI • Language Models for IR • PLSI • Towards real semantic search • Entities, Relations, Facts, Events CS 584: Information Retrieval. Math & Computer Science Department, Emory University
The Central Problem in IR Information Seeker Authors Concepts Concepts Query Terms Document Terms Do these represent the same concepts? CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Noisy-Channel Model of IR Information need d1 d2 Query … User has a information need, “thinks” of a relevant document… and writes down some queries dn Task of information retrieval: given the query, figure out which document it came from? document collection CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Transmitter Receiver Decoder How is this a noisy-channel? Source Destination • No one seriously claims that this is actually what’s going on… • But this view is mathematically convenient! message channel message noise Source Destination Information need query terms Encoder channel Query formulation process CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Problems with term-based retrieval • Synonymy • “Power law” vs. “Zipf distribution” • Polysemy • “Saturn” • Ambiguity • “What do frogs eat?” CS 584: Information Retrieval. Math & Computer Science Department, Emory University
ring jupiter ••• space voyager … saturn ... meaning 1 … planet ... car company ••• dodge ford meaning 2 contribution to similarity, if used in 1st meaning, but not if in 2nd Polysemy and Context • Document similarity on single word level: polysemy and context CS 584: Information Retrieval. Math & Computer Science Department, Emory University
• Mars boasts many extreme geographic features; for example, Olympus Mons, is the largest volcanoin the solar system. • The Galileo probe's mission to Jupiter, the largest planet in the Solar system, included amazing photographs of the volcanoes on Io, one of its four most famous moons. • Even the largest volcanoes found on Earth are puny in comparison to others found around our own cosmic backyard, the Solar System. Ambiguity • Different documents with the same keywords may have different meanings… What is the largest volcano in the Solar System? What do frogs eat? keywords: frogs, eat keywords: largest, volcano, solar, system • Adult frogs eat mainly insects and other small animals, including earthworms, minnows, and spiders. • Alligators eat many kinds of small animals that live in or near the water, including fish, snakes, frogs, turtles, small mammals, and birds. • Some bats catch fish with their claws, and a few species eat lizards, rodents, small birds, tree frogs, and other bats. CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Indexing Word Synsets/Senses • How does indexing word senses solve the synonym/polysemy problem? • Okay, so where do we get the word senses? • WordNet: a lexical database for standard English • Automatically find “clusters” of words that describe the same concepts {dog, canine, doggy, puppy, etc.} concept 112986 I deposited my check in the bank. bank concept 76529 I saw the sailboat from the bank. bank concept 53107 http://wordnet.princeton.edu/ CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Example: Contextual Word Similarity Use Mutual Information: Dagan et al, Computer Speech & Language, 1995 CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Word Sense Disambiguation • Given a word in context, automatically determine the sense (concept) • This is the Word Sense Disambiguation (WSD) problem • Context is the key: • For each ambiguous word, note the surrounding words • “Learn” a classifier from a collection of examples • Use the classifier to determine the senses of words in the documents bank {river, sailboat, water, etc.} side of a river bank {check, money, account, etc.} financial institution CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Example: Unsupervised WSD • Hypothesis: same senses of words will have similar neighboring words • Disambiguation algorithm • Identify context vectors corresponding to all occurrences of a particular word • Partition them into regions of high density • Assign a sense to each such region “Sit on a chair” “Take a seat on this chair” “The chair of the Math Department” “The chair of the meeting” CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Does it help retrieval? • Not really… • Examples of limited success…. Ellen M. Voorhees. (1993) Using WordNet to Disambiguate Word Senses for Text Retrieval. Proceedings of SIGIR 1993. Mark Sanderson. (1994) Word-Sense Disambiguation and Information Retrieval. Proceedings of SIGIR 1994 And others… Hinrich Schütze and Jan O. Pedersen. (1995) Information Retrieval Based on Word Senses. Proceedings of the 4th Annual Symposium on Document Analysis and Information Retrieval. Rada Mihalcea and Dan Moldovan. (2000) Semantic Indexing Using WordNet Senses. Proceedings of ACL 2000 Workshop on Recent Advances in NLP and IR. CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Why Disambiguation Can Hurt • Bag-of-words techniques already disambiguate • Context for each term is established in the query • Heuristics (e.g., always most frequent sense) work better • WSD is hard! • Many words are highly polysemous, e.g., interest • Granularity of senses is often domain/application specific • Queries are short – not enough context for accurate WSD • WSD tries to improve precision • But incorrect sense assignments would hurt recall • Slight gains in precision do not offset large drops in recall CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Outline • Text Information Retrieval: 10-minute overview • Problems with lexical retrieval • Synonymy, Polysemy, Ambiguity • A partial solution: word synsets, WSD • Towards concept retrieval • LSI • Language Models for IR • PLSI • Towards real semantic search • Entities, Relations, Facts, Events CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Latent Semantic Analysis • Perform a low-rank approximation of document-term matrix (typical rank 100-300) • General idea • Map documents (and terms) to a low-dimensional representation. • Design a mapping such that the low-dimensional space reflects semantic associations (latent semantic space). • Compute document similarity based on the inner product in this latent semantic space • Goals • Similar terms map to similar location in low dimensional space • Noise reduction by dimension reduction CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Latent Semantic Analysis • Latent semantic space: illustrating example courtesy of Susan Dumais CS 584: Information Retrieval. Math & Computer Science Department, Emory University
CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Simplistic picture Topic 1 Topic 2 Topic 3 CS 584: Information Retrieval. Math & Computer Science Department, Emory University
CS 584: Information Retrieval. Math & Computer Science Department, Emory University
CS 584: Information Retrieval. Math & Computer Science Department, Emory University
CS 584: Information Retrieval. Math & Computer Science Department, Emory University
CS 584: Information Retrieval. Math & Computer Science Department, Emory University
CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Some (old) empirical evidence • Precision at or above median TREC precision • Top scorer on almost 20% TREC 1,2,3 topics (c.f. 1990) • Slightly better on average than original vector space • Effect of dimensionality: CS 584: Information Retrieval. Math & Computer Science Department, Emory University
CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Problems with term-based retrieval • Synonymy • “Power law” vs. “Zipf distribution” • Polysemy • “Saturn” • Ambiguity • “What do frogs eat?” CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Outline • Text Information Retrieval: 5-minute overview • Problems with lexical retrieval • Synonymy, Polysemy, Ambiguity • A partial solution: synonym lookup • Towards concept retrieval • LSI • Language Models for IR • PLSI • Towards real semantic search • Entities, Relations, Facts, Events CS 584: Information Retrieval. Math & Computer Science Department, Emory University
IR based on Language Model (LM) Information need d1 • A common search heuristic is to use words that you expect to find in matching documents as your query – why, I saw Sergey Brin advocating that strategy on late night TV one night in my hotel room, so it must be good! • The LM approach directly exploits that idea! generation d2 query … … dn document collection CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Formal Language (Model) • Traditional generative model: generates strings • Finite state machines or regular grammars, etc. • Example: I wish I wish I wish I wish I wish I wish I wish I wish I wish I wish I wish … *wish I wish CS 584: Information Retrieval. Math & Computer Science Department, Emory University
multiply Stochastic Language Models • Models probability of generating strings in the language (commonly all strings over alphabet ∑) Model M 0.2 the 0.1 a 0.01 man 0.01 woman 0.03 said 0.02 likes … the man likes the woman 0.2 0.01 0.02 0.2 0.01 P(s | M) = 0.00000008 CS 584: Information Retrieval. Math & Computer Science Department, Emory University
the class pleaseth yon maiden 0.2 0.01 0.0001 0.0001 0.0005 0.2 0.0001 0.02 0.1 0.01 Stochastic Language Models • Model probability of generating any string Model M1 Model M2 0.2 the 0.0001 class 0.03 sayst 0.02 pleaseth 0.1 yon 0.01 maiden 0.0001 woman 0.2 the 0.01 class 0.0001 sayst 0.0001 pleaseth 0.0001 yon 0.0005 maiden 0.01 woman P(s|M2) > P(s|M1) CS 584: Information Retrieval. Math & Computer Science Department, Emory University
P ( | M ) = P ( | M ) P ( | M, ) P ( | M, ) P ( | M, ) Stochastic Language Models • A statistical model for generating text • Probability distribution over strings in a given language M CS 584: Information Retrieval. Math & Computer Science Department, Emory University
P ( ) P ( ) P ( ) P ( ) P ( ) P ( ) P ( | ) P ( | ) P ( | ) P ( | ) = P ( ) P ( | ) P ( | ) Unigram and higher-order models • Unigram Language Models • Bigram (generally, n-gram) Language Models • Other Language Models • Grammar-based models (PCFGs), etc. • Probably not the first thing to try in IR Easy. Effective! CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Using Language Models in IR • Treat each document as the basis for a model (e.g., unigram sufficient statistics) • Rank document d based on P(d | q) • P(d | q) = P(q | d) x P(d) / P(q) • P(q) is the same for all documents, so ignore • P(d) [the prior] is often treated as the same for all d • But we could use criteria like authority, length, genre • P(q | d) is the probability of q given d’s model • Very general formal approach CS 584: Information Retrieval. Math & Computer Science Department, Emory University
P ( | M ( ) ) The fundamental problem of LMs • Usually we don’t know the model M • But have a sample of text representative of that model • Estimate a language model from a sample • Then compute the observation probability M CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Language Models for IR • Language Modeling Approaches • Attempt to model query generation process • Documents are ranked by the probability that a query would be observed as a random sample from the respective document model • Multinomial approach CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Retrieval based on probabilistic LM • Treat the generation of queries as a random process. • Approach • Infer a language model for each document. • Estimate the probability of generating the query according to each of these models. • Rank the documents according to these probabilities. • Usually a unigram estimate of words is used • Some work on bigrams, paralleling van Rijsbergen CS 584: Information Retrieval. Math & Computer Science Department, Emory University
Retrieval based on probabilistic LM • Intuition • Users … • Have a reasonable idea of terms that are likely to occur in documents of interest. • They will choose query terms that distinguish these documents from others in the collection. • Collection statistics … • Are integral parts of the language model. • Are not used heuristically as in many other approaches. • In theory. In practice, there’s usually some wiggle room for empirically set parameters CS 584: Information Retrieval. Math & Computer Science Department, Emory University
CS 584: Information Retrieval. Math & Computer Science Department, Emory University