K-Nearest Neighbors in Machine Learning
350 likes | 397 Vues
Explore the application of k-Nearest Neighbors algorithm in supervised learning for classification and regression tasks. Learn how ML algorithms transform data into fixed-length vectors to predict creditworthiness, genetic testing results, and signature recognition. Discover the significance of feature space and performance metrics in assessing machine learning models.

K-Nearest Neighbors in Machine Learning
E N D
Presentation Transcript
When Should We Apply ML? • A pattern exists • We cannot pin it down mathematically • We have data on it
Supervised Learning • Major ML Categories • Supervised Learning • Classification • Regression • Unsupervised Learning • Reinforcement Learning Many problems can be addressed with supervised learning…
Creditworthiness • Banks would like to decide whetheror not to extend credit to new customers • Good customers pay back loans • Bad customers default • Task: Predict creditworthiness based on: • Salary, Years in residence, Current debt, Age, etc.
Genetic Testing • Microarray (DNA Chip, biochip) • Each spot represents amount of a particular DNA sequence • Different people have different expression profiles • Task: Separate malignant from healthy tissues based on the DNA expression profile
Signature Recognition • Electronic signature pads could be used to authenticate signatures • Task: Does a signature (represented as an image) belong to a specific person?
Text Categorization Task: Categorize documents into predefined categories. For example, categorize news into ‘sports’, ‘politics’, ‘science’, etc. Soft tissue found in T-rex fossil Find may reveal details about cells and blood vessels of dinosaurs Thursday, March 24, 2005 Posted: 3:14 PM EST WASHINGTON (AP) -- For more than a century, the study of dinosaurs has been limited to fossilized bones. Now, researchers have recovered 70-million-year-old soft tissue, including what may be blood vessels and cells, from a Tyrannosaurus rex. Health may be concern when giving kids cell phones Wednesday, March 23, 2005 Posted: 11:14 AM EST SEATTLE, Washington (AP) -- Parents should think twice before giving in to a middle-schooler's demands for a cell phone, some scientists say, because potential long-term health risks remain unclear. Wall Street gears up for jobsSaturday, March 26, 2005: 11:41 AM EST NEW YORK (CNN/Money) - Investors on Inflation Watch 2005 have a big week to look forward to -- or be wary of -- depending on how you look at it. Probe finds atmosphere on Saturn moon Thursday, March 17, 2005 Posted: 11:17 AM EST LOS ANGELES, California (Reuters) -- The space probe Cassini discovered a significant atmosphere around Saturn's moon Enceladus during two recent passes close by, the Jet Propulsion Laboratory said on Wednesday
ML Problem Components • Task: What are we trying to do? • Important to be sure that our example (training) data is useful • Experience: What data do we provide the algorithm? • Defines the input (and output) to the learning system and the data on which it bases its decisions • Performance Metrics: How do we measure how well the system is doing? • Gives us an objective measure to judge the learning process • Also allows comparison between competing methods
Components of Supervised Learning • Task: What are we trying to do? • Predict the target variable for a given example • Experience: What data do we provide the algorithm? • A training set of paired examples and target variables • Performance Metrics: How do we measure how well the system is doing? • Classification accuracy on a (separate) testing set This is typical for supervised learning (classification) problems.
Data Representation • Inputs are quite different • Creditworthiness (demographic information) • Microarray (expression profile) • Document (natural language) • Images • ML algorithms need a fixed representation of data • Usually (fixed-length) vectors
Representing People? • Problem: Predict creditworthiness based on: • Salary, Years in residence, Current debt, Age, etc.
Representing Microarray Data? Each spot represents the abundance of specific DNA sequences in a target
Representing Documents? • Soft tissue found in T-rex fossil • Find may reveal details about cells and blood vessels of dinosaurs • Thursday, March 24, 2005 Posted: 3:14 PM EST • WASHINGTON (AP) -- For more than a century, the study of dinosaurs has been limited to fossilized bones. Now, researchers have recovered 70-million-year-old soft tissue, including what may be blood vessels and cells, from a Tyrannosaurus rex. • Health may be concern when giving kids cell phones • Wednesday, March 23, 2005 Posted: 11:14 AM EST • SEATTLE, Washington (AP) -- Parents should think twice before giving in to a middle-schooler's demands for a cell phone, some scientists say, because potential long-term health risks remain unclear.
Feature Space • Each feature vector, X, lives in feature space • Vector length determines dimensionality
Classification (in feature space) x2 ? ? ? ? x1
Classification • Given: a set of examples (xi,yi) • sampled from some distribution D • called the ‘training set’ • Learn:a function f which classifies ‘well’ examples xjsampled from D • Y is the ‘target variable’ x2 ? ? ? ? x1
Classification • Given an input vector, x • Assign it to one of K discrete classes Ck • where k = 1, … , K • Each input is assigned to one class • Binary (K =2) Classification is the most common • Examples with yi=+1 are called ‘positive examples’ • Examples with yi=-1 are called ‘negative examples’ • Now, our first ML algorithm…
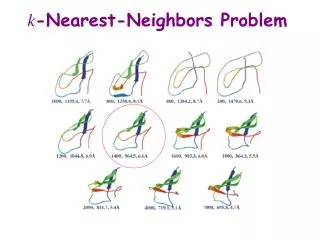
Nearest Neighbor (NN) Classification Toy example: two classes, 2D feature vectors. k-NN classification For a given query point q, assign the class of the nearest neighbour. k = 1 Compute the k nearest neighbours and assign the class by majority vote. k = 3
NN Classification? • Is this a good algorithm? • Why or why not? For a given query point q, assign the class of the nearest neighbour. k = 1 Compute the k nearest neighbours and assign the class by majority vote. k = 3
NN Pros & Cons • Expensive (Time & Space) • Basic version: O(Nd) complexity for both storage and query time • Pre-sort training examples into fast data structures (kd-trees) • Pre-sorting often increases the storage requirements • Remove redundant data (condensing) • Limited with High-Dimensional Data • “Curse of Dimensionality” • Required amount of training data increases exponentially with dimension • Computational cost also increases dramatically • However, k-NN can work quite well in practice • With lots of training data, it’s provably good
Example: Digit Recognition • Yann LeCunn – MNIST Digit Recognition • Handwritten digits • 28x28 pixel images: d = 784 • 60,000 training samples • 10,000 test samples • Nearest Neighbor is competitive
k-NN in Practice • What distance measure to use? • Often Euclidean distance is used • Locally adaptive metrics • More complicated with non-numeric data, or when different dimensions have different scales • Choice of k? • Cross-validation (we’ll cover this later) • 1-NN often performs well in practice • k-NN needed for overlapping classes • Re-label all data according to k-NN, then classify with 1-NN • Reduce k-NN problem to 1-NN through dataset editing
NN in Feature Space • Let’s find the regions of feature space closest to each training point… • Voronoi decomposition • Each cell contains one sample • Every location within the cell is closer to that sample than to any other sample
Decision Regions • Every query point will be assigned the classification of the sample within that cell • The decision boundaryseparates the class regions based on the 1-NN decision rule • Knowledge of this boundary is sufficient to classify new points • The boundary itself is rarely computed. We either: • retain only points necessary to generate an identicalboundary • retain only points necessary to generate a similar boundary
Condensing • Aim is to reduce the number of training samples • Retain only the samples that are needed to define the decision boundary • Decision Boundary Consistent – a subset whose nearest neighbor decision boundary is identical to the boundary of the entire training set • Consistent Set --- – a subset of the training data that correctly classifies all of the original training data • Minimum Consistent Set – smallest consistent set Original data Condensed data Minimum Consistent Set
Condensing • Initialize subset with a single training example • Classify all remaining samples using the subset, and transfer an incorrectly classified sample to the subset • Return to 2 until no transfers occurred or the subset is full • Condensed Nearest Neighbor (CNN) Hart 1968 • Incremental • Order dependent • Neither minimal nor decision boundary consistent • O(n3) for brute-force method • Can follow up with reduced NN [Gates72] • Remove a sample if doing so does not cause any incorrect classifications Produces consistent set
Condensing • Condensed Nearest Neighbor (CNN) Hart 1968 • Incremental • Order dependent • Neither minimal nor decision boundary consistent • O(n3) for brute-force method • Can follow up with reduced NN [Gates72] • Remove a sample if doing so does not cause any incorrect classifications • Initialize subset with a single training example • Classify all remaining samples using the subset, and transfer an incorrectly classified sample to the subset • Return to 2 until no transfers occurred or the subset is full
Condensing • Condensed Nearest Neighbor (CNN) Hart 1968 • Incremental • Order dependent • Neither minimal nor decision boundary consistent • O(n3) for brute-force method • Can follow up with reduced NN [Gates72] • Remove a sample if doing so does not cause any incorrect classifications • Initialize subset with a single training example • Classify all remaining samples using the subset, and transfer an incorrectly classified sample to the subset • Return to 2 until no transfers occurred or the subset is full
Condensing • Condensed Nearest Neighbor (CNN) Hart 1968 • Incremental • Order dependent • Neither minimal nor decision boundary consistent • O(n3) for brute-force method • Can follow up with reduced NN [Gates72] • Remove a sample if doing so does not cause any incorrect classifications • Initialize subset with a single training example • Classify all remaining samples using the subset, and transfer an incorrectly classified sample to the subset • Return to 2 until no transfers occurred or the subset is full
Condensing • Condensed Nearest Neighbor (CNN) Hart 1968 • Incremental • Order dependent • Neither minimal nor decision boundary consistent • O(n3) for brute-force method • Can follow up with reduced NN [Gates72] • Remove a sample if doing so does not cause any incorrect classifications • Initialize subset with a single training example • Classify all remaining samples using the subset, and transfer an incorrectly classified sample to the subset • Return to 2 until no transfers occurred or the subset is full Done!
Condensing • Condensed Nearest Neighbor (CNN) Hart 1968 • Incremental • Order dependent • Neither minimal nor decision boundary consistent • O(n3) for brute-force method • Can follow up with reduced NN [Gates72] • Remove a sample if doing so does not cause any incorrect classifications • Initialize subset with a single training example • Classify all remaining samples using the subset, and transfer an incorrectly classified sample to the subset • Return to 2 until no transfers occurred or the subset is full Done!
Condensing • Condensed Nearest Neighbor (CNN) Hart 1968 • Incremental • Order dependent • Neither minimal nor decision boundary consistent • O(n3) for brute-force method • Can follow up with reduced NN [Gates72] • Remove a sample if doing so does not cause any incorrect classifications • Initialize subset with a single training example • Classify all remaining samples using the subset, and transfer an incorrectly classified sample to the subset • Return to 2 until no transfers occurred or the subset is full Done! Done!
Where are we with respect to NN? • Simple method, pretty powerful rule • Very popular in text mining • Seems to work well for this task • Can be made to run fast • Requires a lot of training data • Condense to remove data that are not needed
Recap • Introduced binary classification • Very common machine learning problem • Feature Space Model • Data set as points in a high dimensional space • Nearest-Neighbor Classification • Simple, powerful classification algorithm • Considers feature distances • Implies decision boundaries