Probabilistic self-organizing maps for qualitative data
This paper presents a novel probabilistic self-organizing map (SOM) designed specifically for qualitative data. Traditional SOMs struggle with non-continuous data due to their reliance on distance measures for clustering. This new model utilizes probabilistic methods, eliminating the need for such measures, allowing for effective learning from categorical data. By implementing the Chow–Liu algorithm to establish a maximum mutual information spanning tree and using the Robbins–Monro algorithm for parameter estimation, this method showcases a promising approach for handling qualitative data without exhaustive computation.


Probabilistic self-organizing maps for qualitative data
E N D
Presentation Transcript
Probabilistic self-organizing maps for qualitative data Ezequiel Lopez-Rubio NN, Vol.23 2010, pp. 1208–1225 Presenter : Wei-Shen Tai 2010/11/17
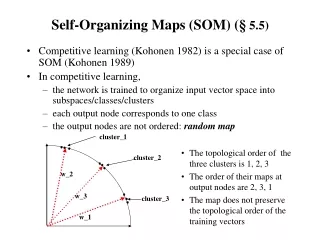
Outline • Introduction • Basic concepts • The model • Experimental results • Conclusions • Comments
Motivation • Non-continuous data in self-organization map • Re-codify the categorical data to fit the existing continuous valued models (1-of-k coding )or impose a distance measure on the possible values of a qualitative variable (distance hierarchy). • SOM depends heavily on the possibility of adding and subtracting input vectors, and on a proper distance measure among them.
Objective • A probability-based SOM • Without the need of any distance measure between the values of the input variables.
Chow–Liu algorithm • Obtain the maximum mutual information spanning tree. • Compute the probability of input x belonged to the tree.
Robbins–Monro algorithm • A stochastic approximation algorithm • Its goal is to find the value of some parameter τ which satisfies • A random variable Y which is a noisy estimate of ζ • This algorithm proceeds iteratively to obtain a running estimation θ (t) of the unknown parameter τ • where ε(t) is a suitable step size. (similar to LR(t) in SOM)
Map and units • Map definition • Each mixture component iis associated with a unit in the map. • Structure of the units
Self-organization • Find BMU • Learning method
Initialization and summary • Initialization of the map • Summary • 1. Set the initial values for all mixture components i. • 2. Obtain the winner unit of an input xt and the posterior responsibilities Rti of the winner. • 3. For every component i, estimate its parameters πi(t),ψijh(t) and ξijhks(t). • 4. Compute the optimal spanning tree of each component. • 5. If the map has converged or the maximum time step T has been reached, stop. Otherwise, go to step 2.
Experimental results • Cars in three graphic results
Conclusion • A probabilistic self-organizing map model • Learns from qualitative data which do not allow meaningful distance measures between values.
Comments • Advantage • This proposed model can handle categorical data without distance measure between units (neurons) and inputs during the training . • That is, categorical data are handled by mapping probability instead of 1-of-k coding and distance hierarchy in this model. • Drawback • The size of weight vector will explosively grow as the number of categorical attributes and their possible values. That makes these computational processes become complex as well. • It fits for categorical data but mixed-type data. • Application • Categorical data in SOMs.