Download

1 / 14
140 likes | 236 Vues
Learn about a novel approach combining ahead pipelining, alloyed history, and perceptron theory to create a high-accuracy branch predictor with reduced latency and improved performance. This presentation covers motivation, theory, related works, results, and conclusions.

E N D
An Ahead Pipelined Alloyed Perceptron with Single Cycle Access Time David Tarjan (CS) Kevin Skadron (CS) Mircea R. Stan (ECE) University of Virginia
The whole presentation in one slide • Perceptron: Best predictor yet, basic unit is table plus adder • Ahead pipeline it and precompute, so it has eff. latency 1 and shorter pipeline • Accuracy does not suffer:
Talk Outline • Motivation & Perceptron Theory • Related Work • Ahead Pipelining a Perceptron • Precomputing a local hist. perceptron • Results • Conclusion
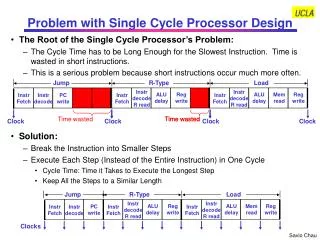
Motivation Main Problems in Branch Prediction: • Accuracy (larger tables, more logic) • Latency (smaller tables, less logic) • Multiple Branch/Trace/Stream/etc. per cycle We address these points Tradeoff!
Motivation • Two recent innovations (both by Jiménez): • Perceptrons: simplest neural network, better accuracy than any previously known predictor(MICRO’01) • Ahead pipelining: Start prediction early, hide latency of prediction, allows access to large tables(HPCA’03) • Use of alloyed history: reduces wrong history branch mispredictions(PACT’00)
Related Work • Perceptron Branch Predictor: lots of work by Jiménez(HPCA’01, MICRO’03) • Perceptron continued: new work by Seznec(TR 1554, 1620) and Ipek (Cornell) • Ahead: Gshare.fast(Jiménez, HPCA’03), EV8 Bpred Adaption(Seznec, ISCA’03) • Precomputation: Original 2-level Branch Predictor Paper(Yeh & Patt, Micro’91)
Conclusion • Ahead Pipelining solves latency problem • Precomputation allows use of local history in a fast predictor • Alloyed Perceptron may offer better accuracy