Download

1 / 22
220 likes | 367 Vues
Learn how to derive the normal distribution function starting with the standard normal distribution and incorporating polar integration principles. Explore expected values and transformations for a deeper understanding.

E N D
Derivation of the Normal Distribution Lecture VI
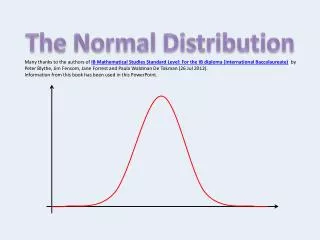
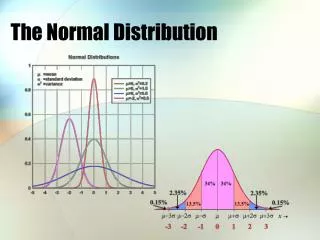
Derivation of the Normal Distribution Function • The order of proof of the normal distribution function is to start with the standard normal:
First, we need to demonstrate that the distribution function does integrate to one over the entire sample space, which is - to . This is typically accomplished by proving the constant. • Let us start by assuming that
Polar Forms • Polar Integration: The notion of polar integration is basically one of a change in variables. Specifically, some integrals may be ill-posed in the traditional Cartesian plane, but easily solved in a polar space. • By polar space, any point (x,y) can be written in a trigonometric form:
As an example, take Some of the results for this function are:
The workhorse in this proof is Greene’s theorem. We know from univariate calculus that • In multivariate space, this becomes
General Normal Distribution • The expression above is the expression for the standard normal. A more general form of the normal distribution function can be derived by defining a transformation function.
Expected Values • Definition 2.2.1. The expected value or mean of a random variable g(X) noted by E[g(X)] is
The most general form used in this definition allows for taking the expectation of the function g(X). Strictly speaking, the mean of the distribution is found where g(X)=X, or
Theorem 2.2.1. Let X be a random variable and let a, b, and c be constants. Then for any functions g1(X) and g2(X) whose expectations exist: • E[ag1(X) + bg2(X) + c]=aE[g1(X)] + bE[g2(X)] + c. • If g1(X) 0 for all X, then E[g1(X)] 0. • If g1(X) g2(X) for all X, then E[g1(X)] E[g2(X)] • If ag1(X) b for all X, then aE[g1(X)] b