SGN23 The Organization of the Human Genome
SGN23 The Organization of the Human Genome. 2% of DNA actually consists of coding regions (exons), or codes for rRNA or tRNA 5% might be regulatory regions associated with genes (proximal and distal control elements, etc.) 20% of genome consists of introns
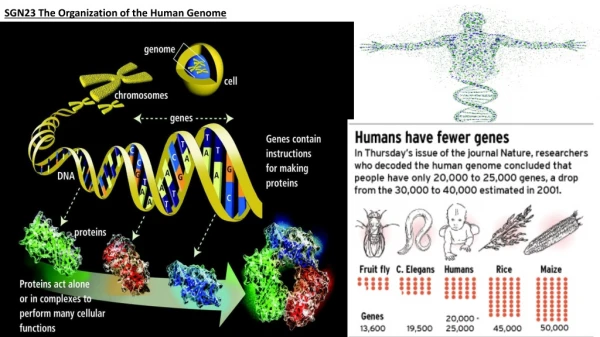

SGN23 The Organization of the Human Genome
E N D
Presentation Transcript
2% of DNA actually consists of coding regions (exons), or codes for rRNA or tRNA • 5% might be regulatory regions associated with genes (proximal and distal control elements, etc.) • 20% of genome consists of introns • 15% is called unique noncoding regions (pseudogenes) • 44% repetitive DNA, including transposons and related sequences • 14% repetitive DNA unrelated to transposons; of human genome • = @100% In humans, only a small part of the genome includes or is directly associated with genes, while the remainder serves other purposes or no purpose at all
Only about 1.5% of DNA actually consists of coding regions (exons), or codes for rRNA or tRNA Exons largely represent protein domains Another 5% might be regulatory regions associated with genes (proximal and distal control elements, etc.) 20% of genome consists of introns
20% of genome consists of introns Some highly conserved regions - Perhaps essential for alternative mRNA splicing? Perhaps regulatory function? – suggests important function
15% is called unique noncoding regions (pseudogenes) Fragments of genes or copies of genes that do not lead to functional protein
Much of genome is composed of DNA that repeats sequences, much of which seems to serve no function; 2 categories Repetitive DNA, including transposons and related sequences; 44% of human genome (interspersed repeats) Repetitive DNA unrelated to transposons; 14% of human genome (tandem repeats)
Repetitive DNA, including transposons and related sequences; 44% of human genome Transposable elements– 100’s to 1000’s of bps long; groups with similar sequences scattered throughout genome; “jump” around the chromosomes
Simple transposons Simplest transposons are insertion sequences – units involving bracketing sequences (inverted repeats) and typically gene needed to make enzyme necessary for transposition 2 types • Move about using “cut and paste” or “copy and paste” method • Requires transposase, made by gene in transposon
Retrotransposons – make mRNA intermediate that is transcribed back into DNA Requires reverse transcriptase, made by gene in transposon (also found in retroviruses – viral evolution or origin?)
Composite transposons – basically two transposons that bracket genes, acting as one large transposon; often include more than just transposition genes
Included in this group are sequences with similarities to transposable elements but without ability to jump, or very low rate of transposition L1 sequences – low rate of transposition; 17% of human genome Alu elements – similar to retrotransposons; make RNA but do not reinsert into genome; 10% of human genome
Transposons and other repetitive elements have been implicated in some mutations that contribute to spontaneous cancer or other diseases
Repetitive DNA unrelated to transposons; tandem repeats; 14% of human genome 2 categories Large segment repeats – units 10,000’s to 100,000’s of bps that are duplicated throughout genome; mostly noncoding regions and when copies of genes, typically not transcribed; due to duplication mistakes during replication or unequal crossing over? When did all of these duplications and other mistakes occur?
Short sequence DNA – many copies of tandemly repeated short sequences (5 to 500 bps), typically repeated 100’s of thousands of times Number of short tandem repeats differs from person to person, which is what primarily generates different sized bands used in DNA fingerprinting and other types of genetic analysis Include telomere and centromere regions, indicating function of some of these repeating units
Back to the genes… Within the coding region, of note are gene families (collection of identical or very similar genes per haploid set of chromosomes), which probably have evolved by duplication of ancestral genes Identical gene families Nonidentical gene families Pseudogenes
Identical gene families – ex. histone proteins and rRNA coding regions
Nonidentical gene families – ex. for alpha and beta forms of globins used to make hemoglobins (p 352) Both alpha and beta globins are made from families of genes that each make different versions of the subunits, the gene family also includes several pseudogenes Versions expressed during development in the uterus have greater affinity for oxygen than adult versions In humans here are 339 related olfactory receptor genes and 297 OR pseudogenes scattered among 21 chromosomes
Origin of Y chromosome Events that added to and changed the genome Origin of disease and also evolution Duplication of entire chromosome sets Alteration of chromosomal structures Changes to the gene
Duplication of entire chromosome sets (mistakes in meiosis) Origin of diploidy and polyploidy
Alteration of chromosomal structures Comparison of species shows that fusion, duplication, deletions, inversions of large sections of chromosomes made during meiosis and recombination are part of evolution
Example – globin gene families Ancestral gene (predates split of plant and animal lineage approximately 1.5 bya) duplicates (slippage during replication or unequal crossing over) and diverges (mutation) into alpha and beta families about 450 – 500 million years ago Duplication within each family followed by divergence produced copies Slippage of template strand could cause deletion Slippage of new strand could cause duplication
Changes to the gene Point mutations – silent, nonsense, missence Changes to parts of the gene Duplication of exons creates proteins with repetitive structures (for example multipass transmembrane proteins) Duplication of gene regions also allows for proteins with highly repetitive amino acid sequences (example collagen) Duplication of gene regions involved in origin of genes that are alternatively spliced (exon shuffling)
We been studying… • Regulated gene expression in prokaryotes and eukaryotes • The Human Genome The result of billions of years of change Random events that have changed the genome Viral and bacterial infection – transposons and related regions = 44% of genome (?) Chromosomal rearrangements (example: the Y chromosome) Including mistakes during meiosis (crossing over) and replication (for example, slippage) Results in repetitive DNA, gene families and the expansion of the coding region Now we are studying… • Differential gene expression How do we get from egg + sperm to zygote to 100 trillion cells, all with genomic equivalency, yet behaving as different and distinct cell types? How do cells become specialized/differentiated?