Asynchronous Pipelined Ring Interconnection for SoC
This project explores the implementation of an asynchronous pipelined ring interconnection aimed at facilitating communication between system-on-chip (SoC) elements operating at differing clock frequencies. The project leverages VHDL design techniques to create a synchronous component that ensures optimal performance while showcasing the capabilities of asynchronous logic. Students Ziv Zeev Shwaitser and Chen Damishian will employ FPGA technology for realization, addressing key challenges such as speed, area efficiency, fairness, and ease of extensibility. Important testing and validation methods will be demonstrated.


Asynchronous Pipelined Ring Interconnection for SoC
E N D
Presentation Transcript
Asynchronous Pipelined Ring Interconnection for SoC Supervisor: Nitzan Miron Students: Ziv Zeev Shwaitser Chen Damishian Based on the article: “SELF-TIMED COMMUNICATION PLATFORM FOR SYSTEM-ON-CHIP DESIGN” Pasi Liljeberg, Juha Plosila, and Jouni Isoaho Electronics and Communication Systems Dept. of Information Technology University of Turku, Finland
מטרת הפרויקט • במעבדה ל-VHDL, תוכנן רכיב המבצע סינכרון בין אלמנטים העובדים בתדר שעון שונה אחד מהשני, תוך שימוש בארכיטקטורה שנקראת Pipelined Ring, במדיניות תזמון אסינכרונית. הפרויקט יוסבר בהמשך. • בפרויקט במעבדה זאת, נרצה לממש מערכת זאת על רכיב FPGA, תוך בנית מערכת שלמה שמשתמשת בתשתית הנתונה. • מטרות: • להתנסות במימוש על גבי רכיב מתוכנת מסוג FPGA, עם לוגיקה אסינכרונית. • להוכיח את נכונות התכנון. סימולציות ב-VHDL אינן ממדלות את העולם נכון, ונותנות השהיה קבועה לכל שער, דבר המקשה בדיקת מירוצים ו-hazards בלוגיקה אסינכרונית. • להשתמש בתכנון הנכון, ולהוכיח כי הביצועים הינם אופטימליים, יחסית למימושים האחרים לפתרון הבעיה (כפי שיוצגו בהמשך).
הפרויקט הקודם - הגדרת הבעיה • נתונים processing elements, אשר כל אחד מהם עובד בתדר שעון שונה. • נדרש לאפשר מעבר מידע בין כל זוג רכיבים במערכת, כאשר יש לקחת בחשבון: • מהירות (שמידע יגיע מנקודה לנקודה מהר ככל האפשר). • שטח (להימנע מיתירות בחומרה, כמו חיבור בין כל זוג אלמנטים). • הגינות (סימטריה בין האלמנטים, בהקשר של זמן תגובה וזמן העברה). • אפשרות להרחבה פשוטה (extendability) (לאפשר מערכת גנרית, שניתנת להתאמה למספר משתנה של אלמנטים, תוך מינימום תקורה).
פתרונות אפשריים לבעיה – מבחינת תזמונים • שימוש בתדר שעון משותף. • כל המערכת עובדת בתדר שעון שהוא תדר השעון של האלמנט האיטי ביותר. • המערכת עובדת לאט, הפתרון אינו אופטימלי (כפי שנראה בהמשך). • מערכת אסינכרונית. GALS (Globally Asynchronous Locally Synchronous). • כל אלמנט עובד בתדר שעון שונה. הסינכרון נעשה על ידי לוגיקה אסינכרונית (אשר את עקרונותיה נתאר בהמשך). • אופטימלי מבחינת מהירות (המידע מועבר כאשר הוא מוכן, בצורה אסינכרונית). אין צורך לעבוד בתדר שעון של הרכיב האיטי ביותר. • ניתן להרחבה בקלות, שכן המערכת עובדת נכון עבור טווח תדרים גדול.
טופולוגיה של המערכת • חיבור נקודה לנקודה בין כל זוג אלמנטים. • חסרונות: • תופס הרבה שטח. (חיבור בין כל נקודה ונקודה). • אינו ניתן להרחבה בקלות. (יש לקשר בין כל אלמנט ואלמנט). • יתרון: • מאפשר מקביליות. (העברת מידע לאלמנטים שונים במקביל). • חיבור על ידי Bus. • יכול להיעשות על ידי bus משותף, או pipelined bus.
Bus משותף • המערכת מורכבת מהרכיבים הבאים: • N האלמנטים. • ה-bus עצמו, המחובר לכל האלמנטים. • בקר המבקר על הכתיבה ל-bus, ומבטיח שרק אלמנט אחד יכתוב בכל פעם. • אופן העברת המידע מתבצע בשלבים הבאים: • שלב 1: האלמנט המשדר מבקש שליטה על ה-bus מהבקר. • שלב 2: כאשר השליטה התקבלה, האלמנט כותב את המידע על ה-bus, עם ציון הנמען. • שלב 3: המידע משודר על ה-bus לכל האלמנטים. • שלב 4: הנמען קורא את המידע מה-bus. • יתרונות: • חיסכון בשטח. Data path משותף. • העברת מידע מהירה בין כל שני אלמנטים. (המסלול הוא מסלול ישיר, על ה-bus). • חסרונות: • אינו מאפשר מקביליות. (רק העברה אחת בו זמנית). • מצריך בקר המבצע arbitration. אינו ניתן להרחבה בקלות. 1 2 4 3
Pipelined bus • הרעיון: • כל שלב הוא אוטונומי, ומבצע העברה של המידע לשלב הבא, או לאלמנט המחובר אליו. • מתנהג כמו Pipeline, שלבים שונים מתבצעים במקביל. • יתרונות: • מאפשר מקביליות. (העברת מידע במקביל במסלול הכחול ובמסלול הירוק). • ניתן להרחבה בקלות. אינו מצריך בקר מסובך. • חסרון: • זמן העברת המידע תלוי במרחק בין שני האלמנטים. (ככל שהאלמנטים רחוקים יותר, המעבר נעשה דרך מספר גדול יותר של שלבים). • חוסר סימטריה. (עבור האלמנטים בקצוות, יהיה זמן העברה ממוצע גדול יותר).
הפרויקט שלנו – Ring architecture • יתרון: כל היתרונות של pipelined bus. • חסרון: יש צורך בתמיכה ב-deadlock.
הסבר - Deadlock • הגדרה: מצב של deadlock במערכת הוא מצב בו שניים או יותר רכיבים מנועים מלהתקדם, כאשר כל אחד מהם מחכה למשאבים שיתפנו על ידי המשכו של האחר. גרף תלויות המתאר מצב של deadlock
מצב של deadlock במערכת pipelined bus • ב-pipelined bus, ה-deadlock הוא מסוג circular wait, אשר יכול להיגרם כאשר כל שלב מחכה להתפנות השלב הבא, לפני שיתפנה בעצמו על ידי העברת המידע הלאה. • בהמשך נתאר כיצד מקרה זה מטופל.
תיאור שלב בודד במערכת • רכיב בודד במערכת הוא בעל המנשק הבא: • מנשק ל-bus לקבלת ושליחת בקשות. • מנשק ל-processing element לקבלת ושליחת בקשות.
מבנה השלב הבודד • התקשורת עם ה-bus נעשית בפרוטוקול 2 phase handshake. • התקשורת הפנימית נעשית בפרוטוקול 4 phase handshake. • נדרשים ממירים בכניסה וביציאה. HOST B U S B U S
מבנה השלב הבודד • תפקיד ה-input control הוא לקבל מידע חדש על ה-bus, לדגום אותו ב-latch, ולהכין אותו לעיבוד ביחידה הבאה. • ה-input control שולח בקשה בפרוטוקול 4 phase handshake. • כאשר עולה סיגנל ה-req, ה-latch נועל את המידע.
מבנה השלב הבודד • תפקיד ה-forward control הוא לנתב את המידע למקום המתאים, בהתבסס על הכתובת. • המידע יכול להיות מועבר לאלמנט הנוכחי, או לאלמנט הבא. • אם המידע מועבר ל-processing element, בקשה בפרוטוקול 4 phase handshake מועברת אל ה-output FIFO. • אם המידע מועבר לאלמנט הבא, בקשה מועברת אל ה-output control. כאשר יוצאת הבקשה, המידע ננעל ב-latch הבא. • הפעולה נעשית במקביל לטיפול בבקשות הבאות ב-input control.
מבנה השלב הבודד • תפקיד ה-output control הוא להעביר את המידע לשלב הבא. • מידע יכול להגיע מהשלב הקודם או מהאלמנט הנוכחי. • יש צורך לבצע ארביטרציה, לבחירת המקור לבקשה. • יש לממש מנגנון למניעת deadlock.
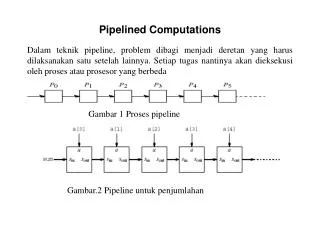
המערכת המוצעת • המערכת המוצעת מממשת מעבד העובד בארכיטקטורת מחסנית. • המעבד מורכב מיחידות שונות, מבוזרות ואוטונומיות, המתקשרות ביניהם על גבי ה-Pipelined Ring. • כל יחידה עובדת בתדר שעון אחר. • מבנה היחידות והתקשורת ביניהן יוסבר בהמשך.
ארכיטקטורת מחסנית • מבנה הנתונים המרכזי בשימוש המעבד הוא מחסנית. • מחסנית מממשת מעבר של נתונים במדיניות LIFO (Last In First Out). • מחסנית הינה מערך של איברים, עם מצביע לראש במערך, שהוא האיבר האחרון שנכנס. • כאשר נתון נכתב למחסנית, ראש המחסנית גדל באחד, ונתון נכתב למיקום החדש של ראש המחסנית. • כאשר נתון נקרא מהמחסנית, הוא נקרא מהמקום אליו מצביע ראש המחסנית, וראש המחסנית קטן באחד. הנתון נמחק מהמחסנית. ראש המחסנית. איברים חדשים יכנסו למקום שמעליו. איברים יקראו מהמקום אליו מצביע הראש. בסיס המחסנית. האיבר הראשון שנכנס אחרי שהמחסנית התרוקנה.
ארכיטקטורת מחסנית • במעבד המממש ארכיטקטורת מחסנית, הקלט הוא נתונים חדשים, ופעולות. • כאשר נתון חדש מגיע, הוא נכתב לראש המחסנית. • כאשר פעולה מסוימת מגיעה, הארגומנטים שלה נקראים מהמחסנית, הפעולה מחושבת, והתוצאה שלה נכתבת לראש המחסנית. • לדוגמא, הקלט 1 2 +. בהתחלה, המחסנית ריקה.
ארכיטקטורת מחסנית • במעבד המממש ארכיטקטורת מחסנית, הקלט הוא נתונים חדשים, ופעולות. • כאשר נתון חדש מגיע, הוא נכתב לראש המחסנית. • כאשר פעולה מסוימת מגיעה, הארגומנטים שלה נקראים מהמחסנית, הפעולה מחושבת, והתוצאה שלה נכתבת לראש המחסנית. • לדוגמא, הקלט 1 2 +. הנתון הראשון נכתב. 1
ארכיטקטורת מחסנית • במעבד המממש ארכיטקטורת מחסנית, הקלט הוא נתונים חדשים, ופעולות. • כאשר נתון חדש מגיע, הוא נכתב לראש המחסנית. • כאשר פעולה מסוימת מגיעה, הארגומנטים שלה נקראים מהמחסנית, הפעולה מחושבת, והתוצאה שלה נכתבת לראש המחסנית. • לדוגמא, הקלט 1 2 +. הנתון השני נכתב. 2 1
ארכיטקטורת מחסנית • במעבד המממש ארכיטקטורת מחסנית, הקלט הוא נתונים חדשים, ופעולות. • כאשר נתון חדש מגיע, הוא נכתב לראש המחסנית. • כאשר פעולה מסוימת מגיעה, הארגומנטים שלה נקראים מהמחסנית, הפעולה מחושבת, והתוצאה שלה נכתבת לראש המחסנית. • לדוגמא, הקלט 1 2 +. הארגומנטים לפעולה נקראים מהמחסנית.
ארכיטקטורת מחסנית • במעבד המממש ארכיטקטורת מחסנית, הקלט הוא נתונים חדשים, ופעולות. • כאשר נתון חדש מגיע, הוא נכתב לראש המחסנית. • כאשר פעולה מסוימת מגיעה, הארגומנטים שלה נקראים מהמחסנית, הפעולה מחושבת, והתוצאה שלה נכתבת לראש המחסנית. • לדוגמא, הקלט 1 2 +. התוצאה של הפעולה נכתבת לראש המחסנית. 3
הרכיבים השונים במערכת • המערכת מורכבת מהרכיבים הבאים: • רכיב קלט, אשר מקבל פקודה ומעבד אותה. (Input). • רכיב פלט, אשר מציג מידע למשתמש. (Output). • רכיב המממש את המחסנית. (Stack). • רכיב המבצע פעולות אריתמטיות ולוגיות. (ALU). • רכיב המממש זיכרון, אליו ניתן לשמור ערכי ביניים מהמחסנית. (Memory). • אפשרויות נוספות: • רכיב הממיר מספרים על המחסנית לתווים (ASCII) שלהם, ומציג אותם. • רכיב המגריל מספרים אקראיים.
מהלך ביצוע פקודה – קבלת מספר מהמשתמש Input המספר נכתב למחסנית Output Stack Memory ALU
מהלך ביצוע פקודה – קבלת מספר מהמשתמש Input המספר נכתב למחסנית המספר מוצג על המסך Output Stack Memory ALU
מהלך ביצוע פקודה – קבלת מספר מהמשתמש Input כאשר מודפס תו סיום, ניתן לעבור לפקודה הבאה המספר נכתב למחסנית המספר מוצג על המסך Output Stack Memory ALU
מהלך ביצוע פקודה – קבלת פעולה מהמשתמש Input הפעולה נשלחת אל ה-ALU Output Stack Memory ALU
מהלך ביצוע פקודה – קבלת פעולה מהמשתמש Input הפעולה נשלחת אל ה-ALU ה-ALU פונה אל המחסנית לקריאת הנתונים Output Stack Memory ALU
מהלך ביצוע פקודה – קבלת פעולה מהמשתמש Input הפעולה נשלחת אל ה-ALU ה-ALU פונה אל המחסנית לקריאת הנתונים Output Stack הנתון מוחזר Memory ALU
מהלך ביצוע פקודה – קבלת פעולה מהמשתמש Input הפעולה נשלחת אל ה-ALU ה-ALU פונה אל המחסנית לקריאת הנתונים Output Stack הנתון מוחזר התוצאה נכתבת למחסנית. Memory ALU
מהלך ביצוע פקודה – קבלת פעולה מהמשתמש Input הפעולה נשלחת אל ה-ALU ה-ALU פונה אל המחסנית לקריאת הנתונים Output Stack הנתון מוחזר התוצאה נכתבת למסך התוצאה נכתבת למחסנית. Memory ALU
מהלך ביצוע פקודה – קבלת פעולה מהמשתמש Input ניתן לעבור לפקודה הבאה הפעולה נשלחת אל ה-ALU ה-ALU פונה אל המחסנית לקריאת הנתונים Output Stack הנתון מוחזר התוצאה נכתבת למסך התוצאה נכתבת למחסנית. Memory ALU
מהלך ביצוע פקודה – שמירת מספר בזיכרון Input הכתובת והערך נקראים מהמחסנית המידע מוחזר Output Stack Memory ALU
מהלך ביצוע פקודה – שמירת מספר בזיכרון Input הכתובת והערך נקראים מהמחסנית המידע מוחזר Output Stack הערך נשמר בזיכרון Memory ALU
מהלך ביצוע פקודה – קריאת מספר מהזיכרון Input הכתובת נקראת מהמחסנית Output Stack Memory ALU
מהלך ביצוע פקודה – קריאת מספר מהזיכרון Input הכתובת נקראת מהמחסנית המידע מוחזר Output Stack Memory ALU
מהלך ביצוע פקודה – קריאת מספר מהזיכרון Input הכתובת נקראת מהמחסנית הכתובת מוחזרת Output Stack הערך נקרא מהזיכרון Memory ALU
מהלך ביצוע פקודה – קריאת מספר מהזיכרון Input הכתובת נקראת מהמחסנית הכתובת מוחזרת Output Stack הערך נקרא מהזיכרון הערך נכתב אל המחסנית Memory ALU
מהלך ביצוע פקודה – קריאת מספר מהזיכרון אל המחסנית Input הכתובת נקראת מהמחסנית הכתובת מוחזרת Output Stack הערך נקרא מהזיכרון הערך נכתב אל המחסנית Memory ALU הערך מודפס על המסך
מהלך ביצוע פקודה – קריאת מספר מהזיכרון אל המחסנית Input הכתובת נקראת מהמחסנית הכתובת מוחזרת ניתן לעבור לפקודה הבאה Output Stack הערך נקרא מהזיכרון הערך נכתב אל המחסנית Memory ALU הערך מודפס על המסך
הערות • במקרה בו מנסים לקרוא כאשר המחסנית ריקה, הודעה מתאימה תוחזר למי שמנסה לקרוא, והפעולה תבוטל. • ניתן להרחיב את המערכת על ידי הוספת אלמנטים נוספים.
לוח זמנים • שבוע 6-7: תכנון הרכיבים (Processing Elements), והפרוטוקולים ביניהם. • בנית המערכת בתוכנת HDL designer. • טעינת הקוד ב-VHDL. • בנית Ring התחלתי. • שבוע -98: מימוש הרכיבים בעזרת תוכנת HDL designer. • מימוש על ידי שימוש בכלי התוכנה, כמו תרשים בלוקים, תרשים זרימה, ומכונת מצבים. • ביצוע סימולציה של הרכיבים בנפרד. • להעלות את כרטיס FPGA בלי המערכת הנתונה. • שבוע 10: להעלות את כרטיס FPGA בלי המערכת הנתונה, ולבדוק דרכים להתממשקות עם הרכיב. • בדיקת אופן הפעולה של הרכיב. • בדיקת הפרוטוקולים על ה-bus של הרכיב. • שבוע 11-12: מימוש המנשק בין המערכת הנתונה ובין כרטיס FPGA הנתון. • מימוש רכיב אשר מתקשר עם ה-bus של כרטיס FPGA, ועם המערכת הנתונה. • שבוע 13-14: ביצוע סינתיזה וסימולציה של המערכת. • טעינת הכרטיס ובדיקת המימוש על ידי סימולציה. • בדיקת אפשרויות נוספות להרחבה.