General nucleic acid Sequence databases
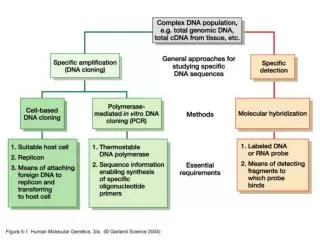
General nucleic acid Sequence databases. EMBL :(European Molecular Biology Laboratory) http://www.ebi.ac.uk/Information/ GenBank : NCBI (National Center for Biotechnology Information) http://www.ncbi.nlm.nih.gov/ DDBJ : DNA Data Bank of Japan


General nucleic acid Sequence databases
E N D
Presentation Transcript
General nucleic acid Sequence databases • EMBL:(European Molecular Biology Laboratory) http://www.ebi.ac.uk/Information/ • GenBank: NCBI (National Center for Biotechnology Information) http://www.ncbi.nlm.nih.gov/ • DDBJ: DNA Data Bank of Japan http://www.ddbj.nig.ac.jp/ Entry name; accession number; version number
General protein Sequence databases • SWISS-PROT • PIR • PRF/SEQDB • PDB: It is the largest data bank of three-dimensional (3-D) biological macromolecular structure data. coding sequences (CDS): from translation • TrEMBL • GenPret:
SWISS-PROT is a highly curated database that contains excellent documentation. SWISS-PROT systematically merges variants and fragments into a single entry, but is greatly lagging behind the growth of the DNA data banks. • PIR contains more sequences, including numerous “really sequenced” oligopeptides, but is not that tightly curated. • The “automatic” data banks such as TrEMBL and GenPept are even larger, but contain little documentation and sometimes conceptual translations that are not actually found in nature.
BLAST Basic Local Alignment Search Tool • The BLAST algorithm breaks the query sequence into short fragments, or “words,” and looks for an identical or close match between those words and words from the database sequences. When such a match or “hit” is encountered, the hit is extended in both directions to generate a local alignment segment. The quality of each alignment is quantified in a score, and the high-scoring segment pairs (HSPs) are reported in a table.
BLASTN, which compares a nucleotide query sequence with a nucleotide sequence database; BLASTP, which compares a protein query sequence with a protein sequence database; BLASTX, which compares a nucleotide query sequence translated in all six open reading frames with a protein sequence database; TBLASTN, which compares a protein query sequence with a nucleotide sequence database dynamically translated in all six open reading frames; and TBLASTX, which compares a six-frame translation of a nucleotide query sequence with the six-frame translations of a nucleotide sequence database. http://www.ddbj.nig.ac.jp/
Sequence alignment Chapter 5 Measuring Genetic Change
D=s+wg W=1 P1 0+1x2=2 P2 2+1x1=3
W=1 P1 0+1x2=2 P2 2+1x1=3 W 小 gap 衝擊小 Gap多 D=s+wg W=2 P1 0+2x2=4 P2 2+2x1=4 Gap多 or 序列變 異大, W 可選小 W 大 gap 衝擊大 Gap少 W=3 P1 0+3x2=6 P2 2+3x1=5 Gap 少 or 序列保守, W 可選大
The cost for every pair of possible amino acid replacements defines a cost matrix that can be used to score the alignment. Protein sequence alignment programmes typically use matrices derived from empirical comparisons of protein sequences
D=s+wg As alignment, How to select W • #z97619 AATCAA-TAG TTTTTTAATT GAAAACTGGA ATGAATGGTT TGACGAG-AA • #z97620 AATCAA-TAG TTTTTTAATT GGAAACTGGG ATGAATGGTT TGACGAA-AA • #u18065 TAATCATTAG TTTCTTAATT AGGGGCTTGA ATGAAGGGAT TGACGAGAAA • #u18066 TAATCATTAG TTTCTTAATT AGGGGCTTGA ATGAATGGAT TGACGAGAAA • #u18069 AATCA-TTAG TCTCTTAATT AGAGGCTTGA ATGAATGGTT TAACGAG-AA • #u18070 AATCA-TTAG TCTCTTAATT GGGGGCTTGA ATGAATGGTT TAACGAG-AA • #u18071 AATCA-TTAG TTTCTTAATT AGAGGCTTGA ATGAATGGTT T-ACGAG-AA • #u18068 AATCAGTTAG TTTCTTAATT AGAGGCTTGA ATGAATGGTT TAACGAG-AA • #u18073 AATCA-TTAG TTTCTTAATT AGGGGCTTGT ATGAATGGTT TGACGAG-AA • #u18074 AATCA-TTAG TTTCTTAATT AGAGGCTTGA ATGAATGGTT TCACGAG-AA • #u18072 AATCA-TTAG TTTCTTAATT AGAGGCTTGT ATGAATGGTT TGACGAG-AA • #u18064 AATCA-TTAG TTTCTTAATT AGAGGCTGGA ATGAATGGTT TGACGAG-AA • #u18067 AATCA-TTAG TTTCTTAATT AGAGGCTGGA ATGAATGGTT TGACGAG-AA • #af514505 AATCA-TTAG TTTCTTAATT GGGGACTGGA ATGAATGGTT TGACGAG-AA • #z97617 AATCA-TTAG TCTCTTAATT AGAGACTGGA ATGAAGGGTT TAACAAG-AA • #z97621 AATCA-TTAG TCTTTTAATT GAAGGCTGGT ATGAATGGTT TGACGAG-GA • #z97623 AATCA-TTAG TCTTTTAATT GAAGACTGGA ATGAATGGTT TGACGAG-GA
#z97619 TTATATAAAA TTTTATGTTT ACTTTATTTT TATAT---TT TATATATATT • #z97620 ATAT---AAT TTTGTTTTTA CTTTTATTTT TATAT---TA AAAAAATATT • #u18065 GATTTTATAT TATTTTAGTT TAGATTTTTA AATATAATTT TTATAATGTT • #u18066 GATTTTATAT TATTTTAGTT TATATTTTTA AATATAATTT TTATAATGTT • #u18069 ATTTTTATAT TATTTTGGTT T--ATTTTAA AATAAAATTT TTATAATGTT • #u18070 ATTTTTATAT TATTTTGGTT T--ATTTTAA AATAAAATTT TTATAGTGTT • #u18071 ATTTTTATAT TATTTTGGTT T--ATTTTTA AGTATAATTT TTATAATGTT • #u18068 AATTTTATAT TATTTTGGTT T--ATTTTTA AATATAATTT TTACTATGTT • #u18073 AAATTTATAT TATTTTAGTT T--ATTTTTA AGTATAAATT TTTAAATGTT • #u18074 AGTTTTGTAT TATTTTAGCT T--ATCTTTT AATATAAGTT TTTTAATGTT • #u18072 AATTTTTTAT TATTTTAGTT T--ATCTTTT AATATAGATT TTT-AATGTT • #u18064 ATTTAATATT TCTTTTA--- -TTATCTTTT TATATTAAAT GT-TGATGTT • #u18067 ATTTAATATT TTTTTTA--- -TTATCTTTT TATATTAATT GT-TGATGTT • #af514505 AATTAATTTT TATTATATAG TTTATTTTTT AATGTTAATT TT-TATTGTT • #z97617 -ATTTAATTT TGTTTTTTTG TAAATTTTGT TACTATTAAT TCAAAATATT • #z97621 TGTAATGTAT TTTTGGATTG ----TTTTTT TACATGCATT A-GTTATATT • #z97623 TTTATATTTG TATATGATAG ----TTTTGA AATATATTTT ATATTATATT
If indels were weighted 4, transversions 2, and transitions 1, the morphological character data were weighted 4. Leading and trailing gaps were weighted one-half internal gaps. These parameters, insertion:deletion cost (indel) and transversion:transition ratio (Tv:Ti) were varied In all cases where morphological data were included, character transformations for morphology were weighted as equal to the indel cost.
ATCGATATGCTT G C T C G A 3 changes 3 differences 。 。 G C T C G A C . . . 4 changes 3 differences . . G C T C T G A C 5 changes 3 differences
Tv or Ts Among genera Tv Ts Tv: 顛換取代 Among species In the same genus Within sibling species Ts: 轉換取代 Tvs
Still A Change to A
Remain identical Transition Transversion
Saturated effect in DNA mutation 1. GTTCTCAGAATC 2. GATCACAGAAAC T C G A T A
鞘蛋白基因之取代趨勢: Ts: 轉換取代 Tv: 顛換取代 Total 轉換取代速率為顛換取代的 4 倍 (0.8/0.2)
結論RNA 的二級結構限制了 5’UTR 的變異性 • 無論是短期(群內)或長期(群間)演化的結果均顯示RNA 的二級結構是必須的 • RNA 的二級結構有其穩定性, 分離株必須有特定的二級結構, 保留下來的可能性才高 (群間). • 5’UTR正負股的二級結構各有其穩定性. • 5’UTR正負股的二級結構有不同的功能, 兩種不同的演化力量導致 promoter 成為hypervariable region.
植物園麻竹相關之satBaMV5’ UTR 之二級結構進化趨勢 DL-I DL-II DL-III DL-IV DL-6V 1997 BSL6 1995 1998 I A5 I A2 A3 IV III II BSL6 6Va I-8 A1 I-6 6Vb A1