Opinion Fraud Detection in Online Reviews Using Network Effects
Explore a collective classification approach to identify fake reviewers and reviews in online platforms. The study leverages network effects, user behavior, and linguistic clues to trace fraudulent activity. An inference algorithm, Loopy Belief Propagation, is used for scalable approximation. Real data results show the effectiveness in detecting fake reviews. Competing with traditional classifiers, the study unveils the significance of side information and network effects in revealing fraudulence. The framework aims at scalability, incremental fraudulence scoring, and exploit partial labels while learning. Experiment results on both real and synthetic data show better accuracy in spotting fake reviews.


Opinion Fraud Detection in Online Reviews Using Network Effects
E N D
Presentation Transcript
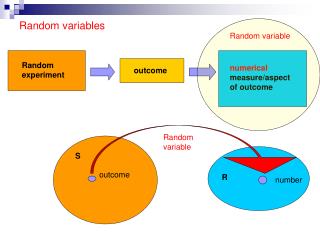
Opinion Fraud Detection in Online Reviews using Network Effects • users: `honest’ / `fraudster’ • reviews: `genuine’ / `fake’ • products: `good’ / `bad’ • review sentiments (+: thumbs-up, -: thumbs-down) • the user-product review network (bipartite) i Leman Akoglu Stony Brook University leman@cs.stonybrook.edu Rishi Chandy Carnegie Mellon University rishic@cs.cmu.edu Christos Faloutsos Carnegie Mellon University christos@cs.cmu.edu Approach Problem Results and Conclusions Problem Formulation: A Collective Classification Approach Datasets Objective function utilizes pairwise Markov Random Fields (Kindermann&Snell, 1980): • SWM: All app reviews of entertainment category (games, news, sports, etc.) from an anonymous online app store database • As of June 2012: • * 1, 132, 373 reviews • * 966, 842 users • * 15,094 software products (apps) • Ratings: 1 (worst) to 5 (best) • II) Also simulated fake review data (with ground truth) edge signs node labels as random variables compatibility potentials observed neighbor potentials prior belief Competitors Compared to 2 iterative classifiers (modified to handle signed edges): I) Weighted-vote Relational Classifier (wv-RC) (Macskassy&Provost, 2003) II) HITS (honesty-goodness in mutual recursion) (Kleinberg, 1999) Which reviews do/should you trust? Inference A Fake-Review(er) Detection System • Finding best assignments is the inference problem, NP-hard for general graphs. • We use a computationally tractable (linearly scalable with network size) approximate inference algorithm called Loopy Belief Propagation (LBP) (Pearl, 1982). • Iterativeprocess in which neighbor variables • “talk” to each other, passing messages • When consensus reached, calculate belief • signed Inference Algorithm (sIA): Desired properties that such a system to have: Performance on simulated data: (from left to right) sIA, wv-RC, HITS Property 2: Side information Information on behavioral (e.g. login times) and linguistic (e.g. use of capital letters) clues should be exploited. Property 1: Network effects Fraudulence of reviews/reviewers is revealed in relation to others. So review network should be used. Real-data Results “I (variable x1) believe you (variable x2) belong in these states with various likelihoods…” Top 100 users and their product votes: Property 3: Un/Semi-supervision Methods should not expect fully labeled training set. (humans are at best close to random) “bot” members? I) Repeat for each node: Property 4: Scalability Methods should be (sub)linear in data/network size. Property 5: Incremental Methods should compute fraudulence scores incrementally with the arrival of data (hourly/daily). Problem Statement + (4-5) rating o (1-2) rating A network classification problem: Given Classify network objects into type-specific classes: Top-scorers matter: II) At convergence: Compatibility: Conclusions • Novel framework that exploits network effects to automatically spot fake review(er)s. • Problem formulation as collective classification in bipartite networks • Efficient scoring/inference algorithm to handle signed edges • Desirable properties: i) general, ii) un/semi-supervised, iii) scalable • Experiments on real&synthetic data: better than competitors, finds real fraudsters. Scoring: Before After