Efficient Hashing-Based Algorithms for Query Optimization in Database Systems
Understand the fundamentals of hashing-based algorithms for query execution and optimization in database systems. Learn about hash basics, partitioning relations, grouping, aggregation, union, intersection, difference, and the hash-join algorithm. Explore the process of executing queries and optimizing logical and physical query plans. Gain insights into the operation of database management system components and how user queries are translated into database operations. Discover techniques to reduce I/O operations and improve the efficiency of handling large data sets using hashing-based approaches.


Efficient Hashing-Based Algorithms for Query Optimization in Database Systems
E N D
Presentation Transcript
Query executionhashing based Two pass algorithms —Gaurang Patel— (205)
Agenda • Terminology • Hash Basics • Partitioning relation by hashing • Hash-based Grouping and Aggregation • Union, Intersection and Difference • Hash-Join Algorithm • Conclusion
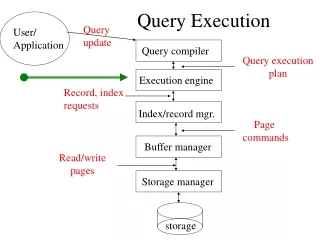
Terminology • Query optimization -- Logical Query plan -- Physical plan • Query execution: -- Query processor- group of DBMS components -- Converts user queries into database operations • Operation • Relation- arguments of operation
Basics of Hash • Large data • Hash functions to store large relations Memory buffers • Gain factor of M in the size of relations
Partitioning Relations by Hashing Algorithm:
Hash-based Grouping and Aggregation • Tuples from same block foes to same bucket • Hash key depends on grouping attributes • First pass: Process each bucket in turn. • Second pass: Only one record per group.
Union, Intersection and Difference • Binary operation- same hash function for both arguments • Union: R U S • First Pass -- 2(M-1) buckets -- Avoid duplicates • Same for R ∩ S, R – S..
Union, Intersection and Difference • I/O operations needed: -- B(R) + B(S) -- 2 more for hashing -- Total: 3(B(R) + B(S)) • For, two pass algorithm: -- min(B(R),B(S)) ≤ M2
Hash-Join Algorithm • R(X,Y) ►◄ S(Y,Z) • Same as other binary operations • Only difference in hash key, Y • I/O operations: -- 3(B(R)+B(S)) -- Two pass require min(B(R),B(S)) ≤ M2 -- Further techniques to reduce number of I/O operations









![Query Execution [15]](https://cdn2.slideserve.com/4816696/query-execution-15-dt.jpg)