QUERY EXECUTION
QUERY EXECUTION. Chapter 15. Query EXECUTION. The query processor is the group of components of a DBMS that turns user queries and data-modification commands into a sequence of database operations and executes those operations.


QUERY EXECUTION
E N D
Presentation Transcript
QUERY EXECUTION Chapter 15
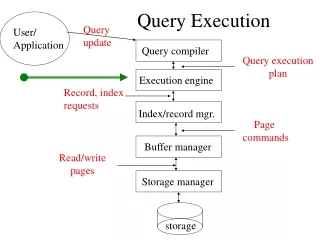
Query EXECUTION • The query processor is the group of components of a DBMS that turns user queries and data-modification commands into a sequence of database operations and executes those operations. • Since SQL lets us express queries at a very high level, the query processor must supply a lot of detail regarding how the query is to be executed. • In Chapter 15, concentration is more on Query execution. • Query Execution: It is the algorithms that manipulate the data of the database.
Query EXECUTION • The principal methods for execution of the operations of relational algebra differ in their basic strategy of • Scanning, • Hashing, • Sorting, and • Indexing • Assumption about the amount of available main memory. • Assumption that the arguments of the operation are too big to fit in memory and might have significantly different costs and structures.
Query Compilation Query compilation is divided into 3 major steps: • Parsing, in which a parse tree construct the structure and query. • Query rewrite, in which the parse tree is converted to an initial query plan, which is an algebraic representation of the query. This initial plan is then transformed into an equivalent plan that is expected to require less time to execute • Physical Plan Generation, where the abstract query plan is converted into physical query plan. The physical plan is represented by an expression tree. The physical plan also includes details such as how the queried relations are accessed, and when and if a relation should be sorted.
15.1 Introduction to physical-query-plan operators • Physical query plans are built from : • Operator: operators each of which implements one step of the plan. • Physical operators: They do not involve operations of relational algebra. e.g: Scanning a table
15.1.1 Scanning Tables For scanning a table we have two different approach: • Basic Scan: A relation R which Scan the Entire Data • Specific Scan: A relation R that selects the tuples from database which satisfy certain predicate for relation R. The Basic approach to locate the tuples are: • Table scan • Relation R is stored in secondary memory with its tuples arranged in blocks which can be retrieved one by one. • Index scan • If there is an index on any attribute of relation R, then we can use this index to get all the tuples of R. • we can use the index not only to get all the tuples of the relation it indexes, but to get only those tuples that have a particular value in the attribute that form the search key for the index.
15.1.2 sorting while scanning tables • Sorting is the major concern while scanning the table. • Reasons why we need sorting while scanning tables: • Various algorithms for relational-algebra operations require one or both of their arguments to be sorted relation. • The query could include an ORDER BY clause requiring that a relation be sorted. There are several ways that sort-scan (Physical-Query-plan operator) can be implemented: • If we are to produce a relation R sorted by attribute a, and if there is a B-tree index on a, then index scan is used. • If relation R is small enough to fit in main memory, then we can retrieve its tuples using a table scan or index scan. • If R is too large to fit in main memory, then the multiway merging approach is used.
15.1.3 The Computation Model for Physical Operators • A query generally consists of several operations of relational algebra, and the corresponding physical query plan is composed of several physical operators. • Good query processor chooses physical plan operators wisely and is able to estimate the "cost" of each operator we use. • Disk I/O can be used as a measure of cost. • If the operator produces the final answer to a query, and that result is indeed written to disk, then the cost depends on the size of the answer, and not on how the answer was computed. • When the answer is passed to some device other than disk then the disk I/O cost of the output either is zero or depends upon application data.
15.1.4 parameter for measuring costs • Estimates of cost are essential if the optimizer has to determine which query plans is likely to execute fastest. • We need a parameter to represent the portion of main memory that the operator uses and some parameters to measure size of arguments. This calculates the Main memory buffer required for an operation. • These parameters, measuring size and distribution of data in a relation are often computed periodically to help the query optimizer choose physical operators. • The parameter families which are essential for cost estimation are: • Size of relation R to hold number of blocks B containing data. • Number of tuples T in R to calculate tuples which would fit in one B • Number of distinct values V appearing in a column
15.1.5 I/o cost for scan operators Parameters for measuring costs • Parameters that mainly affect the performance of a query are: • The cost mainly depends upon size of memory block on the disk • The size in the main memory affects the performance of a query. • Buffer space availability in the main memory at the time of execution of the query. • Size of input and the size of the output generated • This are the number of disk I/O’s needed for each of the scan operators. • If a relation R is clustered, then the number of disk I/O’s is approximately B where B is the number of blocks where R is stored. • If R is clustered but requires a two phase multi way merge sort then the total number of disk I/O required will be more. • If R is not clustered, then the number of required disk I/0's is generally much higher or equal to T.
15.1.6 Iterators for Implementation of Physical Operators • The Iterator allows a consumer of the result of the physical operator to get the result one tuple at a time. • The three major functions of an iterator: • Open() we have to start process by getting tuples and initialize the data structure and perform operation. • Getnext() this function returns the next tuple in result • Close() finally closes all operation and function












![Query Execution [15]](https://cdn2.slideserve.com/4816696/query-execution-15-dt.jpg)