Download
1 / 87
870 likes | 1.01k Vues
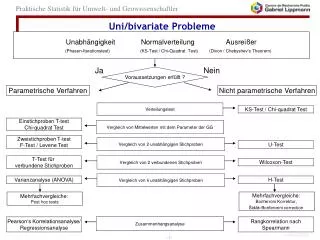
Uni/bivariate Probleme. Unabhängigkeit Normalverteilung Ausreißer (Phasen-Iterationstest) (KS-Test / Chi-Quadrat Test) (Dixon / Chebyshev's Theorem). Ja. Nein. Voraussetzungen erfüllt ?. Parametrische Verfahren. Nicht parametrische Verfahren.

E N D
Uni/bivariate Probleme Unabhängigkeit Normalverteilung Ausreißer (Phasen-Iterationstest) (KS-Test / Chi-Quadrat Test)(Dixon / Chebyshev's Theorem) Ja Nein Voraussetzungen erfüllt ? Parametrische Verfahren Nicht parametrische Verfahren Verteilungstest KS-Test / Chi-quadrat Test Einstichproben T-test Chi-quadrat Test Vergleich von Mittelwerten mit dem Parameter der GG Zweistichproben T-test F-Test / Levene Test Vergleich von 2 unabhängigen Stichproben U-Test T-Test für verbundene Stichproben Vergleich von 2 verbundenen Stichproben Wilcoxon-Test Vergleich von k unabhängigen Stichproben Varianzanalyse (ANOVA) H-Test Mehrfachvergleiche: Post hoc tests Mehrfachvergleiche: Bonferroni Korrektur, Šidàk-Bonferonni correction Zusammenhangsanalyse Pearson‘s Korrelationsanalyse/ Regressionsanalyse Rangkorrelation nach Spearmann
Categorization of multivariate methods Data analysis Data mining Reduction Classification Data Relationships Principal Component Analysis Factor Analysis Factor Analysis Discriminant Analysis Multiple Regression Principal Component Regression Correspondence Analysis Homogeneity Analysis Hierarchical Cluster Analysis Multidimensional Scaling Linear Mixture Analysis Partial Least Squares - 2 Non-linear PCA Procrustes Analysis K-Means Artificial Neural Networks Partial Least Squares -1 Canonical Analysis Support Vector Machines ANN SVM ANN SVM
Vorgehen beim statistischen testen: • Aufstellen der H0/H1-Hypothese • Ein- oder zweiseitige Fragestellung • Auswahl des Testverfahrens • Festlegen des Signikanzniveaus (Fehler 1. und 2. Art) • Testen • Interpretation
Fehler 1. und 2. Art In Population gilt H0 H1 richtig, mit 1-α β-Fehler P(H0¦H1)= β Entscheidung aufgrund der Stichprobe H1 H0 α-Fehler P(H1¦H0)= α richtig, mit 1- β
Bestimmen von Irrtumswahrscheinlichkeiten sei eine normalverteilte Stichprobe (nach 1. Grenzwertsatz) unbekannter Herkunft, mit Probe stammt aus der Eifel Probe stammt aus dem Hunsrück
P-Wert wird gleiner mit > Diff. mit < mit > n Test: Einstichproben Gauss Test mit Wert schneidet 0.62% von NV ab (P-Wert = Irrtumswahrscheinlichkeit) α=5%, ~Z=1.65 H0 muss verworfen werden!
Frage: Welches muss überschritten werden, um H0 mit gerade verwerfen zu können? schneided von der rechten Seite der SNV genau 5% ab
Zweiseitiger Test: schneidet auf jeder Seite der SNV genau 2.5% ab H0 wird knapper abgelehnt! Entscheidung ein-/zweiseitiger Test muss im Vorfeld erfolgen!
Der β-Fehler Kann nur bei spezifischer H1 bestimmt werden! Wir testen, ob sich die Stichprobe mit dem Parameter der Eifelproben verträgt Wert schneidet auf der linken Seite der SNV 10.6% ab. Entscheidet man sich aufgrund des Ereignisses für die H0, so wird man mit einer p von 10.6% einen β-Fehler begehen, d.h. H1 (« Probe stammt aus der Eifel ») verwerfen, obwohl sie richtig ist.
Die Teststärke Die β-Fehlerwahrscheinlichkeit gibt an, mit welcher p die H1 verworfen wird, obwohl ein Unterschied besteht 1- β gibt die p an zugunsten von H1 zu entscheiden, wenn H1 gilt. Bestimmen der Teststärke Wir habe herausgefunden, dass ab einem Wert der Test gerade signifikant wird (« Probe stammt aus der Eifel »)
Bestimmen der Teststärke β-Wahrscheinlichkeit: 0.0179 Teststärke: 1-β =1-0.0179 = 0.9821 Die p, dass wir uns aufgrund des gewählten Signifikanzniveaus (α=5%) zu Recht zugunsten der H1 entscheiden, beträgt 98.21% Determinanten der Teststärke: Mit kleiner werdener Diff. µ0-µ1 verringert sich 1- β Mit wachsendem n vergrössert sich 1- β Mit wachsender Merkmalsstreuung sinkt 1- β
Why multivariate statistics? Remember • Fancy statistics do not make up for poor planning • Design is more important than analysis
Prediction Methods Use some variables to predict unknown or future values of other variables. Description Methods Find human-interpretable patterns that describe the data. Categorization of multivariate methods From [Fayyad, et.al.] Advances in Knowledge Discovery and Data Mining, 1996
y Response Surface yi 0=10 E(yi) i 0 x1 (xi1, xi2) x2 Multiple Linear Regression Analysis The General Linear Model A general linear model can be: • straight-line model • quadratic model (second-order model) • more than one independent variables. E.g.
Multiple Linear Regression Analysis y=x1 + x2 – x1 + 2 x12 + 2 x22
Multiple Linear Regression Analysis Parameter Estimation The goal of an estimator is to provide an estimate of a particular statistic based on the data. There are several ways to characterize estimators: • Bias: an unbiased estimator converges to the true value with large enough sample size. Each parameter is neither consistently over or under estimated • Likelihood: the maximum likelihood (ML) estimator is the one that makes the observed data most likely ML estimators are not always unbiased for small N • Efficient: an estimator with lower variance is more efficient, in the sense that it is likely to be closer to the true value over samples the “best” estimator is the one with minimum variance of all estimators
Multiple Linear Regression Analysis A linear model can be written as is an N-dimensional column vector of observations Where: is a (k+1)-dimensional column vector of unknown parameters is an N-dimensional random column vector of unobserved errors Matrix X is written as The first column of X is the vector , so that the first coefficient is the intercept. The unknown coefficient vector is estimated by minimizing the residual sum of squares
Multiple Linear Regression Analysis Model assumptions The OLS estimator can be considered as the best linear unbiased estimator (BLUE) of provided some basic assumptions regarding the error term are satisfied : • Mean of errors is zero: • Errors have a constant variance: • Errors from different observations are independent of each other: for • Errors follow a Normal Distribution. • Errors are not uncorrelated with explanatory variable:
For a multiple regression model: 1 should be interpreted as change in y when a unit change is observed in x1and x2 is kept constant. This statement is not very clear when x1and x2 are not independent. Misunderstanding: i always measures the effect of xi on E(y), independent of other x variables. Misunderstanding: a statistically significant value establishes a cause and effect relationship between x and y. Multiple Linear Regression Analysis Y X2 Interpreting Multiple Regression Model X1
Multiple Linear Regression Analysis Explanation Power by • If the model is useful… • At least one estimated must 0 • But wait …What is the chance of having one estimated significant if I have 2 random x? • For each , prob(b 0) = 0.05 • At least one happen to be b 0, the chance is: • Prob(b1 0 or b2 0) • = 1 – prob(b1=0 and b2=0) = 1-(0.95)2 = 0.0975 • Implication?
Multiple Linear Regression Analysis Analysis R2 (multiple correlation squared) – variation in Y accounted for by the set of predictors • Adjusted R2. The adjustment takes into account the size of the sample and number of predictors to adjust the value to be a better estimate of the population value. Adjusted R2 = R2 - (k - 1) / (n - k) * (1 - R2) Where: n = # of observations,k = # of independent variables, Accordingly: smaller n decreases R2 value; larger n increases R2 value; smaller k, increases R2 value; larger k, decreases R2 value. • The F-test in the ANOVA table to judge whether the explanatory variables in the model adequately describe the outcome variable. • The t-test of each partial regression coefficient. Significant t indicates that the variable in question influences the Y response while controlling for other explanatory variables.
Multiple Linear Regression Analysis ANOVA where J is an nn matrix of 1s
Multiple Linear Regression Analysis • The R2 statistic measures the overall contribution of Xs. • Then test hypothesis: • H0: 1=… k=0 • H1: at least one parameter is nonzero • Since there is no probability distribution form for R2, F statistic is used instead.
Multiple Linear Regression Analysis F-statistics
Multiple Linear Regression Analysis How many variables should be included in the model? • Basic strategies: • Sequential forward • Sequential backward • Force entire The first two strategies determine a suitable number of explanatory variables using the semi-partial correlation as criterion and a partial F-statistics which is calculated from the error terms from the restricted (RSS1) and unrestricted (RSS) models: where k, k1 denotes the number of lags of the unrestricted and restricted model, and N is the number of observations.
Multiple Linear Regression Analysis The semi-partial correlation Y Z X • Measures the relationshipbetween a predictor and the outcome, controlling for the relationshipbetweenthatpredictor and anyothersalready in the model. • It measures the unique contribution of a predictor to explaining the variance of the outcome.
Multiple Linear Regression Analysis Testing the regression coefficients An unbiased estimator for the variance is The regression coefficients are tested for significance under the Null-Hypothesis using a standard t-test Where denotes the ith diagonal element of the matrix . is also referred to as standard error of a regression coefficient .
Multiple Linear Regression Analysis Which X is contributing the most to the prediction of Y? Cannot interpret relative size of bs because each are relative to the variables scalebut s (Betas; standardized Bs) can be interpreted. a is the mean on Y which is zero when Y is standardized
Multiple Linear Regression Analysis Can the regression equation be generalized to other data? Can be evaluated by • randomly separating a data set into two halves. Estimate regression equation with one half and apply it to the other half and see if it predicts • Cross-validation
Multiple Linear Regression Analysis Residual analysis
e 0 x/E(y) Multiple Linear Regression Analysis The Revised Levene’s test • Divide the residuals into two (or more) groups based the level of x, • The variances and the means of the two groups are supposed to be equal. A standard t-test can be used to test the difference in mean. A large t indicates nonconsistancy.
Multiple Linear Regression Analysis Detecting Outliers and Influential Observations • Influential points are those whose exclusion will cause major change in fitted line. • “Leave-one-out” crossvalidation. • If ei > 4s, it is considered as outlier. • True outlier should not be removed, but should be explained.
Multiple Linear Regression Analysis Generalized Least-Squares Example for a Generalized Least-Square model which can be used instead of OLS-regression in the case of autocorrelated error terms (e.g. in Distributed Lag-Models)
Multiple Linear Regression Analysis SPSS-Example
Multiple Linear Regression Analysis SPSS-Example
Multiple Linear Regression Analysis SPSS-Example Model evaluation
Multiple Linear Regression Analysis SPSS-Example Studying residual helps to detect if: • Model is nonlinear in function • Missing x • One or more assumptions of is violated. • Outliers Model evaluation
ANalysis Of VAriance ANOVA (ONE-WAY) ANOVA (TWO-WAY) MANOVA ANOVA
Comparing more than two groups ANOVA deals with situations with one observation per object, and three or more groups of objects The most important question is as usual: Do the numbers in the groups come from the same population, or from different populations? ANOVA
One-way ANOVA: Example Assume ”treatment results” from 13 soil plots from three different regions: Region A: 24,26,31,27 Region B: 29,31,30,36,33 Region C: 29,27,34,26 H0: The treatment results are from the same population of results H1: They are from different populations ANOVA
Comparing the groups Averages within groups: Region A: 27 Region B: 31.8 Region C: 29 Total average: Variance around the mean matters for comparison. We must compare the variance within the groups to the variance between the group means. ANOVA
Variance within and between groups Sum of squares within groups: Sum of squares between groups: The number of observations and sizes of groups has to be taken into account! ANOVA
Adjusting for group sizes ANOVA Both are estimates of population variance of error under H0 n: number of observations K: number of groups • If populations are normal, with the same variance, then we can show that under the null hypothesis, • Reject at confidence level if
Continuing example -> H0 can not be rejected ANOVA
ANOVA table NOTE:
When to use which method In situations where we have one observation per object, and want to compare two or more groups: Use non-parametric tests if you have enough data For two groups: Mann-Whitney U-test (Wilcoxon rank sum) For three or more groups use Kruskal-Wallis If data analysis indicate assumption of normally distributed independent errors is OK For two groups use t-test (equal or unequal variances assumed) For three or more groups use ANOVA ANOVA
Two-way ANOVA (without interaction) In two-way ANOVA, data fall into categories in two different ways: Each observation can be placed in a table. Example: Both type of fertilization and crop type should influence soil properties. Sometimes we are interested in studying both categories, sometimes the second category is used only to reduce unexplained variance. Then it is called a blocking variable ANOVA
Sums of squares for two-way ANOVA Assume K categories, H blocks, and assume one observation xij for each category i and each block j block, so we have n=KH observations. Mean for category i: Mean for block j: Overall mean: ANOVA
ANOVA table for two-way data Test for between groups effect: compare to Test for between blocks effect: compare to




















