A Markov Random Field Model for Term Dependencies
180 likes | 199 Vues
This paper presents a Markov Random Field (MRF) model to capture dependencies between terms in a text collection. The model improves retrieval effectiveness by incorporating various types of evidence. Three variants of the MRF model are introduced and their impact on retrieval effectiveness is analyzed. Experimental results show that modeling dependencies can significantly improve retrieval performance across different collections. Future work includes exploring alternative potential functions and applying the model to other retrieval tasks.

A Markov Random Field Model for Term Dependencies
E N D
Presentation Transcript
A Markov Random Field Model for Term Dependencies Hongyu Li & Chaorui Chang
Background • Dependencies exist between terms in a collection of text • Estimating statistical models for general term dependencies is infeasible due to data sparsity • Most work on modeling term dependencies in the past has focused on phrases proximity or term co-occurrences
Hypothesis and Solution • Dependence models will be more effective for larger collections than smaller collections • Incorporating several types of evidence into a dependence model will further improve effectiveness • Introducing Markov Random Field
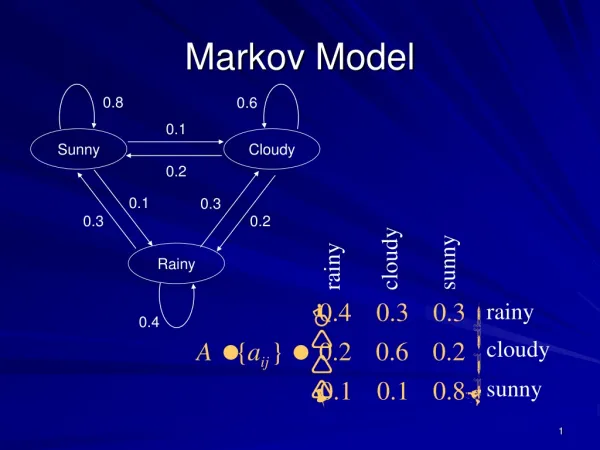
Markov Random Field • Also called undirected graph models , model joint distributions • In the paper used to model the joint distribution over queries Q and documents D • Assume graph G consists of query nodes qi and a document node D • Joint distribution is defined by Where C(G) is the set of cliques in G, each is a non-negative potential function
3 variants of MRF model • Full independence Query terms qi are independent • Sequential dependence Dependence between neighboring query terms • Full dependence All query terms are in some way dependent
Potential functions • Potential function for 2-clique • Contiguously sets of query terms within the clique • Non-contiguous sets of query terms
Ranking • Define the ranking function • Potential function can be parameterized as
Training • Set parameter values • Train the model by directly maximizing mean average precision • Ranking function is invariant to parameter scale, thus Example mean average precision surface for the GOV2 collection using the full dependence model
3.Experimental Resultsanalyze the retrieval effectiveness across different collections • Journal &Press :small homogeneous collections • Web Collections: larger and less homogeneous
3.1 Full Independence variant • the cliques are only members of the set T , and therefore we set= = 0, = 1. • Ranking function :
AvgP refers to mean average precision, P@10 is precision at 10 ranked documents, and µ is the smoothing parameter used. • This results provide a baseline to compare the sequential and full dependence variants Full independence variant results.
3.2 Sequential Dependence variant • Models of this form have cliques in T , O, and U. Ranking function : • The unordered feature function, , has a free parameter N thatallows the size of the unordered window (scope of proximity) to vary. • We explore window sizes of 2, sentence(8), 50, and “unlimited”to see what impact they have on effectiveness.
Show very little difference across the various window sizes. • For the AP, WT10g, and GOV2 collection,the sentence-sized windows performed the best. For the WSJ collection, N = 2 performed the best. • The sequential dependence variant outperforms the full independence variant sequential dependence variant results
3.3 Full Dependence variant • Consists of cliques in T , O and U. ranking function : • We set the parameter N in the feature function to be four times the number of query terms in the clique c. • We analyze the impact ordered and unordered window feature functions have on effectiveness.
AP collection, there is very little difference . • The results for the WSJ collection the ordered features produce a clear improvement over the unordered features, but there is very little difference between using ordered features and the combination of ordered and unordered. • The results for the two web collections, WT10g and GOV2, are similar. In both, unordered features perform better than ordered features, but the combination of both ordered and unordered features led to noticeable improvements in mean average precision. full dependence variant results
Strict matching via ordered window features is more important for the smaller newswire collections, due to the homogeneous, clean nature of the documents • For the web collections, the opposite is true.
4. CONCLUSIONS • Three dependence model variants are described, where each captures different dependencies between query terms. • Modeling dependencies can significantly improve retrieval effectiveness across a range of collections. • Possible future work includes exploring a wider range of potential functions, applying the model to other retrieval tasks and so on.