Recall
Ma. Mb. V E. Precision. Recall. Forecasting Skewed Biased Stochastic Ozone Days: Analyses and Solutions Kun Zhang , Wei Fan , Xiaojing Yuan, Ian Davidson, and Xiangshang Li. What this Paper Offers. Application: more accurate (higher recall & precision) solution to predict “ozone days”

Recall
E N D
Presentation Transcript
Ma Mb VE Precision Recall Forecasting Skewed Biased Stochastic Ozone Days: Analyses and SolutionsKun Zhang, Wei Fan, Xiaojing Yuan, Ian Davidson, and Xiangshang Li
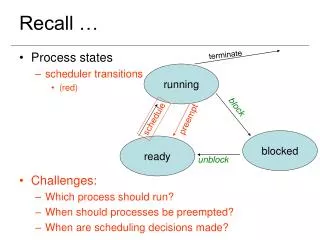
What this Paper Offers • Application: more accurate (higher recall & precision) solution to predict “ozone days” • Interesting and Difficult Data Mining Problem: • High dimensionality and some could be irrelevant features: 72 continuous, 10 verified by scientists to be relevant • Skewed class distribution : either 2 or 5% “ozone days” depending on “ozone day criteria” (either 1-hr peak and 8-hr peak) • Streaming: data in the “past” collected to train model to predict the “future”. • “Feature sample selection bias”: hard to find many days in the training data that is very similar to a day in the future • Stochastic true model: given measurable information, sometimes target event happens and sometimes it doesn’t.
Key Solution Highlights • Non-parametric models are easier to use when “physical or generative mechanism” is unknown. • Reliable conditional probabilities estimation under “skewed, high-dimensional, possibly irrelevant features”, … • Estimate decision threshold predict the unknown distribution of the future
Seriousness of Ozone Problem • Ground ozone level is a sophisticated chemical and physical process and “stochastic” in nature. • Ozone level above some threshold is rather harmful to human health and our daily life.
Drawbacks of current ozone forecasting systems • Traditional simulation systems • Consume high computational power • Customized for a particular location, so solutions not portable to different places • Regression-based methods • E.g. Regression trees, parametric regression equations, and ANN • Limited prediction performances
Ozone Level Prediction: Problems we are facing • Daily summary maps of two datasets from Texas Commission on Environmental Quality (TCEQ)
Challenges as a Data Mining Problem • Rather skewed and relatively sparse distribution • 2500+ examples over 7 years (1998-2004) • 72 continuous features with missing values • Huge instance space • If binary and uncorrelated, 272 is an astronomical number • 2% and 5% true positive ozone days for 1-hour and 8-hour peak respectively
True model for ozone days are stochastic in nature. • Given all relevant features XR, P(Y = “ozone day”| XR) < 1 • Predictive mistakes are inevitable
A large number of irrelevant features • Only about 10 out of 72 features verified to be relevant, • No information on the relevancy of the other 62 features • For stochastic problem, given irrelevant features Xir , where X=(Xr, Xir), P(Y|X) = P(Y|Xr) only if the data is exhaustive. • May introduce overfitting problem, and change the probability distribution represented in the data. • P(Y = “ozone day”| Xr, Xir) 1 • P(Y = “normal day”|Xr, Xir) 0
1 1 2 + 2 + + + - 3 3 - + + Testing Distribution Training Distribution • “Feature sample selection bias”. • Given 7 years of data and 72 continuous features, hard to find many days in the training data that is very similar to a day in the future • Given these, 2 closely-related challenges • How to train an accurate model • How to effectively use a model to predict the future with a different and yet unknown distribution
List of methods: • Logistic Regression • Naïve Bayes • Kernel Methods • Linear Regression • RBF • Gaussian mixture models Ma Mb VE Precision Recall Highly accurate if the data is indeed generated from that model you use! But how about, you don’t know which to choose or use the wrong one? Addressing Challenges • List of methods: • Decision Trees • RIPPER rule learner • CBA: association rule • clustering-based methods • … … • Skewed and stochastic distribution • Probability distribution estimation • Parametric methods • Non-parametric methods • Decision threshold determination through optimization of some given criteria • Compromise between precision and recall use a family of “free-form” functions to “match the data” given some “preference criteria”. • free form function/criteria is appropriate. • preference criteria is appropriates
Reliable probability estimation under irrelevant features • Recall that due to irrelevant features: • P(Y = “ozone day”| Xr, Xir) 1 • P(Y = “normal day”|Xr, Xir) 0 • Construct multiple models • Average their predictions • P(“ozone”|xr): true probability • P(“ozone”|Xr, Xir, θ): estimated probability by model θ • MSEsinglemodel: • Difference between “true” and “estimated”. • MSEAverage • Difference between “true” and “average of many models” • Formally show that MSEAverage ≤ MSESingleModel
Ma Mb VE Precision Estimated probability values 1 fold Estimated probability values 10 fold Estimated probability values 2 fold Concatenate 10CV Recall “Probability- TrueLabel” file PrecRec plot Decision threshold VE TrainingSet Algorithm ….. 10CV Concatenate 1 1 2 + 2 + + + P(y=“ozoneday”|x,θ) Lable 7/1/98 0.1316 Normal 7/3/98 0.5944 Ozone 7/2/98 0.6245 Ozone ……… P(y=“ozoneday”|x,θ) Lable 7/1/98 0.1316 Normal 7/2/98 0.6245 Ozone 7/3/98 0.5944 Ozone ……… - 3 3 - + + Testing Distribution Training Distribution • A CV based procedure for decision threshold selection • Prediction with feature sample selection bias
Classification on future days Whole TrainingSet if P(Y = “ozonedays”|X,θ ) ≥ VE θ Predict “ozonedays” Addressing Data Mining Challenges • Prediction with feature sample selection bias • Future prediction based on decision threshold selected
Probabilistic Tree Models RDT: Random Decision Tree (Fan et al’03) • “Encoding data” in trees. • At each node, an un-used feature is chosen randomly • A discrete feature is un-used if it has never been chosen previously on a given decision path starting from the root to the current node. • A continuous feature can be chosen multiple times on the same decision path, but each time a different threshold value is chosen • Stop when one of the following happens: • A node becomes too small (<= 3 examples). • Or the total height of the tree exceeds some limits: • Different from Random Forest • Single tree estimators • C4.5(Quinlan’93) • C4.5Up,C4.5P • C4.4(Provost’03) • Ensembles • RDT(Fan et al’03) • Member tree trained randomly • Average probability • Bagging Probabilistic Tree (Breiman’96) • Bootstrap • Compute probability • Member tree: C4.5, C4.4 • Original Data vs Bootstrap • Random pick vs. Random Subset + info gain • Probability Averaging vs. Voting
Optimal Decision Boundary from Tony Liu’s thesis (supervised by Kai Ming Ting)
BaselineForecasting Parametric Model • in which, • • O3 - Local ozone peak prediction • • Upwind - Upwind ozone background level • • EmFactor - Precursor emissions related factor • • Tmax - Maximum temperature in degrees F • • Tb - Base temperature where net ozone production begins (50 F) • • SRd - Solar radiation total for the day • • WSa - Wind speed near sunrise (using 09-12 UTC forecast mode) • • WSp - Wind speed mid-day (using 15-21 UTC forecast mode)
Precision Precision Precision Recall Model evaluation criteria • Precision and Recall • At the same recall level, Ma is preferred over Mb if the precision of Ma is consistently higher than that of Mb • Coverage under PR curve, like AUC
Some Coverage Results • 8-hour: recall = [0.4,0.6] Coverage under PR-Curve
8-hour: thresholds selected at the recall = 0.6 • 1-hour: thresholds selected at the recall = 0.6 0.7 0.6 0.5 0.4 Recall 0.3 Precision 0.2 0.1 0 BC4.4 RDT C4.4 Para Some “Action” Results • Previous years’ data for training • Next year for testing • Repeated 6 times using 7 years of data • Annual test • C4.4 best among single trees • BC4.4 and RDT best among tree ensembles • BC4.4 and RDT more accurate than baseline Para • BC4.4 and RDT “less surprise” than single tree
Summary • Procedures to formulate as a data mining problem, • Analysis of combination of technical challenges • Process to search for the most suitable solutions. • Model averaging of probability estimators can effectively approximate the true probability • A lot of irrelevant features • Feature sample selection bias • A CV based guide for decision threshold determination for stochastic problems under sample selection bias
Choosing the Appropriate PET come to our other talk 10:30 RM 402 Signal-noise separability estimation through RDT or BPET Given dataset AUC Score High signal-noise separability >=0.9 < 0.9 Low signal-noise separability Ensemble Ensemble or Single trees Single Tree Ensemble or Single trees Feature types and value characteristics AUC MSE Error Rate Continuous features or categorical feature with a large number of values Single Trees (AUC,MSE,ErrorRate) Categorical feature with limited values Ensemble (AUC,MSE,ErrorRate) MSE, ErrorRate AUC, MSE, ErrorRate AUC, MSE, ErrorRate AUC BPET CFT RDT RDT ( BPET) CFT C4.5 or C4.4
Thank you! Questions?