Download

1 / 28
280 likes | 394 Vues
Explore how value predictions are learned in human brain circuits during associative learning, using neuroimaging techniques and theoretical models such as temporal difference learning. Discover key findings from research experiments conducted at Wellcome Department of Imaging Neuroscience, Institute of Neurology, Queen Square, London.

E N D
Neuroimaging of associative learning John O’Doherty Functional Imaging Lab Wellcome Department of Imaging Neuroscience Institute of Neurology Queen Square, London Collaborators on this project: Peter Dayan Ray Dolan Karl Friston Hugo Critchley Ralf Deichmann Acknowledgements to: Eric Featherstone, Peter Aston
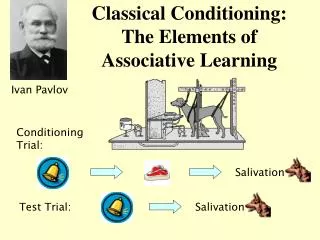
UCS CS Neuroimaging of associative learning Classical conditioning 1/ How Pavlovian value predictions are learned 2/ Where this is implemented in the human brain 3/ Extend approach to instrumental conditioning
Neuroimaging of associative learning How value predictions are learned UCS CS • Learning is mediated by a prediction error (Rescorla and Wagner, 1972; Pearce & Hall, 1980) • δ = (r - v) • where r = reward received on a given trial (UCS) • v = expected reward - value of CS stimulus
CS2 CS Neuroimaging of associative learning • Temporal difference learning (TD learning): • Differs from previous trial based theories - • Predictions are learned about the total future reward available within a trial for each time t in which a CS is presented • (Sutton and Barto, 1989;Montague et al., 1996; Schultz, Dayan and Montague,1997) 0 1 2 3 4 5 Time within trial
Temporal difference learning model UCS CS Before Learning During Learning Unexpected Omission of reward
Reward Learning: Pavlovian Appetitive Conditioning Single unit recordings from dopamine neurons revealed that these neurons produce responses consistent with TD - learning (Schultz, 1998): (1) Transferring their responses from the time of the presentation of the reward to the time of the presentation of the CS during learning. (2) Decreasing firing from baseline at the time the reward was expected following an omission of expected reward. (3) Responding at the time of the reward following the unexpected delivery of reward From Schultz, Montague and Dayan, 1997 Can we find evidence of a temporal difference prediction error in the human brain during appetitive conditioning?
Experimental Set Up • Scanning conducted at 2 Tesla (Siemens) • Taste delivered using an electronic syringe pump • positioned outside the scanner room • On-line measurement of pupillary responses • 13 subjects participated (9 found taste pleasant at end of scanning)
Taste Reward (0.5ml of 1M glucose) CS+omit CS+ 0 0 3 3 6 6 Neutral taste CSneut 0 3 6 Taste Reward (0.5ml of 1M glucose) CS-unexpreward CS- 0 3 6 Experimental Design Ratio of regular to ‘surprise’ trials 4:1
CS+omit 0s 0s 6s 6s 3s 3s CS CS UCS UCS 0s 6s 3s CS UCS 0s 6s 3s CS UCS Statistical Analysis TD related δ responses across the experiment CS-unexpreward CS+ Early Delta at time of CS CS+ Late CS+ trials Delta at time of UCS CS+, CS+omit and CS-unexpreward trials
CS+ — CSneut * B *significant at p<0.05 Results Discriminatory pupillary responses
Results Areas showing signed TD-related PE responses +6 +3 R -3 -6 Random effects p<<0.001 p<0.05 corrected for small volume (ventral striatum) Different learning rates fit some regions better than others (α=0.2 vs. α=0.7) -30 +54 From O’Doherty, Dayan, Friston, Critchley and Dolan. Neuron,2003
CS+omit model real LateCS+ (trials 41-80) Mid CS+ (trials 11-40) 3s 6s 0s 3s 6s 0s CS UCS CS UCS 3s 6s 0s CS UCS Early CS+ (trials 1-10) 3s 6s 0s CS UCS Results CS+omit % signal change Time (secs) CS-unexpreward 3s 6s 0s CS UCS
Interim Conclusions (1) • Responses in a part of human ventral striatum and orbitofrontal cortex can be described by a theoretical learning model: temporal difference learning. • On the basis of evidence from non-human primates, it is likely that a source of TD-learning related activity in these regions is the modulatory influence exerted by the phasic responses of dopamine neurons.
Response-Outcome Stimulus-Response Stimulus-Outcome (Pavlovian) Reward Learning: Instrumental Conditioning
Model of instrumental conditioning: Actor Critic Actor-critic TD(0) learning Follow policy π, in state u, take action a, with probability P[a’,u] (a function of the value of that action) moving from state u to u’. Critic: v=wu δ = ra(u)+v(u’)-v(u) where v(u)= value of state (averaged over all possible actions). Update weights: w(u)=w(u)+εδ Where ε = learning rate. Actor: update policy π, by changing value of state-action pairs (Q) for action a, as well as the value of all other actions a’ Q(a’,u) = Q(a’,u)+ ε(δaa’ – P[a’,u])δ P[a’;u] = probabilty of taking action a’ in state u δ = ra(u)+v(u’)-v(u)
Dorsal vs Ventral Striatum Putative anatomical substrates of actor-critic Ventral striatum = critic Dorsal striatum = actor (Montague et al., 1996) Houk et al., (1995) – suggest matrix/striosome distinction SNigra VTA
+ + 60% probability receive neutral taste 30% probability receive neutral taste Experimental Design Two trial types: 80 trials of each high valence low valence 60% probability receive fruit juice 30% probability receive fruit juice
Experimental Design • The design is split into two ‘sessions’: • Pavlovian and Instrumental (each ~15 minutes in duration). • Order of presentation of sessions counterbalanced across subjects • Used two different fruit juices as the reward: peach juice and • blackcurrant juice. • To control for habituation in the pleasantness of the juices over the course of the experiment a different juice was used in the Pavlovian and Instrumental tasks for each subject. Again this was counterbalanced across subjects. • Instrumental responses from one subjects were used as a ‘yoke’ to the Pavlovian contingencies from another subject.
Instrumental choices * * Significant at p<0.05 Behavioral results
P<0.01 P<0.001 Results: Ventral Striatum PAVLOVIAN CONDITIONING P<0.01 R P<0.001 y=+14 y=+8 INSTRUMENTAL CONDITIONING
Results: Ventral Striatum CONJUNCTION OF INSTRUMENTAL AND PAVLOVIAN CONDITIONING y=+10 y=+8
Results: Dorsal Striatum INSTRUMENTAL CONDITIONING P<0.01 R P<0.001 y=+20 PAVLOVIAN CONDITIONING y=+20
P<0.01 P<0.001 Results: Dorsal Striatum INSTRUMENTAL – PAVLOVIAN CONDITIONING R α = 0.2 Effect size R y=+20 PE_cs PE_ucs PE_cs PE_ucs y=+20 Instrumental task Pavlovian task
Dorsal vs Ventral Striatum Putative anatomical substrates of actor-critic Ventral striatum = critic Dorsal striatum = actor (Montague et al., 1996) Houk et al., (1995) – suggest matrix/striosome distinction SNigra VTA
Conclusions (1) • A temporal difference prediction error signal is present in a part of • the human brain (ventral striatum) during appetitive conditioning. • A putative neural substrate of the reward-related prediction error signal in the striatum is the phasic activity of afferent dopamine neurons. • TD-related response is present in ventral striatum • during Instrumental as well as Pavlovian conditioning • Dorsal striatum has significantly enhanced responses during Instrumental relative to Pavlovian Conditioning
Conclusions (2) • Suggests that actor-critic like process is implemented in human striatum: • -Ventral striatum may correspond to the critic: involved in forming predictions of future reward • -Dorsal striatum may correspond to the instrumental actor: may mediate stimulus-response learning • More generally, demonstrates application of event-related fMRI to test constrained computational models of human brain function.
Neuroimaging of associative learning John O’Doherty Functional Imaging Lab Wellcome Department of Imaging Neuroscience Institute of Neurology Queen Square, London Collaborators on this project: Peter Dayan Ray Dolan Karl Friston Hugo Critchley Ralf Deichmann Acknowledgements to: Eric Featherstone, Peter Aston