Fine recombination mapping in S. cerevisiae using tiling microarrays
460 likes | 657 Vues
Fine recombination mapping in S. cerevisiae using tiling microarrays. Richard Bourgon 20 September 2007 bourgon@ebi.ac.uk. Meiotic recombination. Meiosis… Two divisions, yielding 4 haploid daughter cells. Double-stranded breaks (DSBs) initiate recombination.

Fine recombination mapping in S. cerevisiae using tiling microarrays
E N D
Presentation Transcript
Fine recombination mapping in S. cerevisiae using tiling microarrays Richard Bourgon 20 September 2007 bourgon@ebi.ac.uk
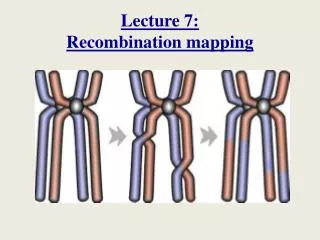
Meiotic recombination Meiosis… • Two divisions, yielding 4 haploid daughter cells. • Double-stranded breaks (DSBs) initiate recombination. • Both crossover and non-crossover resolutions are possible.
Meiotic recombination Meiosis… • Two divisions, yielding 4 haploid daughter cells. • Double-stranded breaks (DSBs) initiate recombination. • Both crossover and non-crossover resolutions are possible. Based on B de Massy, TRENDS in Genetics 19(9), 2003
Meiotic recombination Meiosis… • Two divisions, yielding 4 haploid daughter cells. • Double-stranded breaks (DSBs) initiate recombination. • Both crossover and non-crossover resolutions are possible. Based on B de Massy, TRENDS in Genetics 19(9), 2003
Meiotic recombination Meiosis… • Two divisions, yielding 4 haploid daughter cells. • Double-stranded breaks (DSBs) initiate recombination. • Both crossover and non-crossover resolutions are possible. Based on B de Massy, TRENDS in Genetics 19(9), 2003
Research questions • In S. cerevisiae, where do hotspots occur and what are the local recombination rates? • Do hotspots (binary) or recombination rates (quantitative) correlate with features of DNA sequence or chromatin structure? • How large are conversion regions? Can we identify the various resolution patterns? • What is the relative frequency of the various DSB-repair pathways? • Does the observed pattern among recombination events concur with current models for “interference”? Do mutations impact interference?
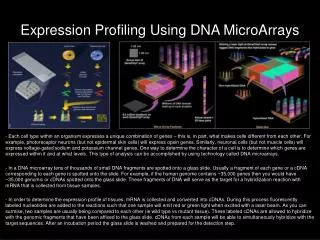
Saccharomyces cerevisiae microarray data • Two strains • S96, isogenic to the common laboratory strain S288c. • YJM789, isogenic to the clinical isolate YJM145. • In alignable regions ≈ 56,000 SNPs, 30,000 insertions and deletions. • Tiling microarrays • ≈ 6.5 M 5µ features, tiling non-repetitive S96 every 4 bases. • ≈ 4% of probes are specific to YJM789 sequence. • Data • 25 parental genomic DNA hybridizations. • 208 wildtype offspring hybridizations. • 20 msh4 mutant offspring hybridizations.
“Single feature polymorphisms” • Hybridization efficiency depends on the number and position of mismatches. • Differential hybridization provides a means of detecting polymorphisms, even when only the reference genome sequence is known: SFPs. • Winzeler et al., Science 281(5380), 1998. • Brem et al., Science 296(5568), 2002. • Steinmetz et al., Nature 416(6878), 2002. • Borevitz et al., Genome Research 13(3), 2003. • Given parental behavior, genotype segregants via supervised classification.
Single-probe methods • Polymorphism detection • Winzeler et al. (and others): ANOVA testing 1 = 1. • Borevitz et al.: moderated t-test using the SAM adjustment. • Brem et al.: moderated t-test. Then cluster all data (parental and segregant) and discard SFPs for which clusters don’t separate the parental data. • Segregant genotyping • ANOVA and t-test methods use the estimated posterior probability of class membership, with a uniform prior on the classes: • Brem et al. augment this: are estimated from clustered data.
S96: CCTCCTGACCGGGATTGAAGTGATAAACATGTCTAGCGTTA YJM789: CCTCCTGACCGGGATTGAACTGATAAACATGTCTAGCGTTA Probe sets: SNP interrogation 6: CTTCACTATTTGTACAGATCGCAAT Probe sets: groups of probes which each exactly map to a unique location, and which interrogate a common polymorphism. 5: CTAACTTCACTATTTGTACAGATCG 4: GGCCCTAACTTCACTATTTGTACAG 2: GACTGGCCCTAACTTCACTATTTGT 1: GGAGGACTGGCCCTAACTTCACTAT 3: GACTGGCCCTAACTTGACTATTTGT
A multi-probe method: SNPScanner Gresham et al., Science 311(5769), 2006: • Model the decrease in a given probe’s intensity in the presence of a single SNP, as a function of • Position within the probe, • Probe response to reference sequence, • Probe GC content, and • Nucleotides surround the SNP position. • Fit model parameters using two sequenced strains with known SNPs. • To genotype a segregant or new strain at a given base, assume probes in a probe set are independent and compute a likelihood ratio: vs. with assumed to be common for both genotypes.
An alternative multi-probe method • Residual correlation remains after centering log intensities for each probe within inferred genotype class: a multivariate approach is justified.
An alternative multi-probe method • Residual correlation remains after centering log intensities for each probe within inferred genotype class: a multivariate approach is justified. • Parental arrays are informative, but do not always provide an ideal model. Supervised classification of offspring (i) wastes information, and (ii) may be misleading.
An alternative multi-probe method • Residual correlation remains after centering log intensities for each probe within inferred genotype class: a multivariate approach is justified. • Parental arrays are informative, but do not always provide an ideal model. Supervised classification of offspring (i) wastes information, and (ii) may be misleading. • Clear division into two distributions is necessary but not sufficient. Quantitative aspects of the inferred clusters are useful.
Semi-supervised, model-based clustering (SSC) Semi-supervised clustering via EM algorithm: • Assume a two-component mixture, with 1 = 2 = 1/2. • (Xi,Yi) with latent class variable Y. Y is known for parental arrays. • Assume X|Y multivariate normal. • Begin with E-step: initialize the unknown Y with any simple clustering scheme: k-means, hierarchical agglomeration, etc. • Iteratively estimate parameters, E(Yi|Xi), parameters, etc. • Classify segregant i based on final estimated E(Yi|Xi). For diagnostic purposes only: • Multivariate Gaussian fit to dimension-reduced parental data. • Unsupervised clustering of offspring data, by EM algorithm, with k{2,3}.
Filtering • Array level • Excess “genotype switching”. • Large RMS residual (Mahalanobis). • Probe set level • High estimated misclassification rate. • Aberrant cluster behavior. • Very unusual genotype ratio. • Call level • Intermediate posterior probability of class membership.
Genotyping accuracy • 82 usable forward sequencing runs. (Reverse similar.) • 16 spores sequenced. • Sequenced regions include 322 array-interrogated SNPs. • Sequenced samples had a range of array qualities. • Sequenced regions focused on single-marker conversions with a range of probe set quality scores.
Genotype call comparison: SNPScanner vs. SSC • Filter for both methods: • Remove probe bad arrays and aberrant probe sets. • Remove probe sets with poorly separated clusters. • Drop calls falling between two observed clusters. • Only consider polymorphisms with at least one S288c-specific probe. • Compute concordance rate between the two methods.
Summary and future work • Summary • Semi-supervised clustering out-performs supervised classification: • Parental data are often not a faithful indicator of offspring behavior. • Offspring clusters contain a lot of information. • Filtering is important for small event detection: • Aberrant or error-prone probe sets create spurious small “events” • Correct distribution estimates are required to detect the latter. • Future work • Exploration and recovery of aberrant probe sets. • Unanticipated polymorphism detection. • Application to a single sequenced genome. • Rate/count adjustments given varying marker spacing. • Hotspots, conversion/crossover ratio, sizes, spacing and interference. • New mms4 mutant…
Acknowledgements • EMBL Heidelberg • Eugenio Mancera Ramos • Lars Steinmetz • Julien Gagneur • Zhenyu Xu • EBI • Wolfgang Huber • EBI, and Istituto Europeo di Oncologia, Milan • Alessandro Brozzi • EBI, and Higgins Lab, University College, Dublin • Paul McGettigan