Protein structure classification
Protein structure classification. CATH and SCOP. Topic 8. Chapters 17 & 18, Gu and Bourne “ Structural Bioinformatics”. SCOP vs. CATH. The basic classification unit is domain . -- A distinct structural unit and may fold as an independent, compact unit.


Protein structure classification
E N D
Presentation Transcript
Protein structure classification CATHand SCOP Topic 8 Chapters 17 & 18, Gu and Bourne “ Structural Bioinformatics”
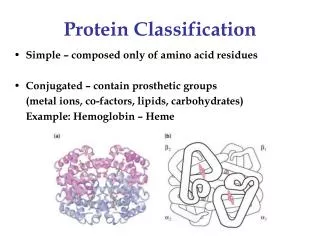
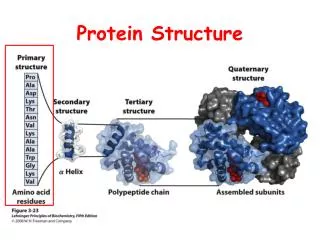
SCOP vs. CATH • The basic classification unit is domain. • -- A distinct structural unit and may fold as an independent, compact unit. • -- Considered as the basic unit of protein folding, function and evolution. • -- Domain partition, either manual or automatic, is not trivial. • CATH is semi-automatic • SCOP is mainly manual (human expertise) low class fold Similarity level relationship superfamily family high clear
Protein domains Pyruvate kinase Elongation faction EF-Tu
SCOP vs. CATH “CATH – A hierarchic classification of protein structure domains” Oregngo et al., Structure, 5: 1093-1108, 1997.
Protein Structure Classification • Why bother? • Provides structural and evolutionary relationship • Provides current fold space • Assists protein structure prediction (details later) • Two popular protein classification databases: • SCOP (Structural Classification Of Proteins ) • http://scop.mrc-lmb.cam.ac.uk/scop/ • Latest release: v1.75 (June 2009) • 110,800 domains • Murzin et al. J. Mol. Biol. 247, 536-540, 1995 • CATH: Class (C), Architecture (A), Topology (T) and Homologous superfamily (H). • http://www.cathdb.info/ • Recent release: v3.5 (Sept 2011) • 173,536 domains • Orengo et al. Structure, 5, 1093-1108, 1997
Hierarchical Structure Classification “CATH – A hierarchic classification of protein structure domains” Oregngo et al., Structure, 5: 1093-1108, 1997.
Hierarchical Structure Classification • SCOP • Class () • Fold (TIM beta/alpha-barrel) • Superfamily (Triosephosphateisomerase) • Family (Triosephosphateisomerase) • CATH • Class () • Architecture (-barrel) • Topology (TIM barrel) • Homologous Superfamily(Aldolase class 1) • Sequence Family (Isomerase)
Hierarchical Structure Classification SCOP C F S F CATH C A T H S Conservation: Typically orthologs 2o structure content High-level structure similarity Lower-level structure similarity
This seems trivial. Why are we wasting valuable class time discussing it? • While a hierarchical description of protein structure is conceptually straightforward, as you will see, automating it is not. Moreover, the domain boundary problem is actually quite difficult. • Also, this discussion is nice in the sense that it ties together a lot of different bioinformatics concepts into one unified effort. Some of these concepts are structural; however, many are not.
Topology vs. Architecture Flavodoxin (toplogy = Rossmanfold) Caution: Due to how secondary structures are interconnected, varying topologies can converge on the same overall architecture. Domain 1 of -lactamase – Same architecture, but different topology aba
An even trickier example “CATH – A hierarchic classification of protein structure domains” Oregngo et al., Structure, 5: 1093-1108, 1997.
The CATH Classification Strategy (1.) Close relatives are identified via sequence comparisons. (2.) Sequence profiles and structure comparison protocols are used to detect more distant homologies. (3.) Structures unclassified at this stage are then examined using both automatic and manual procedures to determine domain boundaries. (4.) Unclassified domain structures are recomputed using the methods employed in steps 2 and 3. (5.) Finally, structure(s) remaining unclassified are manually assigned to existing or new architectures within CATH.
The CATH Classification Strategy Automatic procedure “If a given domain has sufficiently high sequence and structural similarity (ie. 35% sequence identity, SSAP score >= 80) with a domain that has been previously classified in CATH, the classification is automatically inherited from the other domain”. “CATH – A hierarchic classification of protein structure domains” Oregngo et al., Structure, 5: 1093-1108, 1997.
CATH Classification-Domain Assignment • Since the classification is performed on individual domains, therefore the very • first step is to assign domains(find domain boundaries) • Use both automatic and manual techniques • If it has high sequence identity (80%) and structural similarity (SSAP score >= 80) with a protein chain X that has been classified in CATH, use the boundaries of X. • Otherwise, apply several domain partition programs (CATHEDRAL, DETECTIVE (Swindells, 1995), PUU (Holm & Sander, 1994), DOMAK (Siddiqui and Barton, 1995). • Consensus assign automatically • No consensus assign manually. Domain Partition Problem Structure Comparison Problem SSAP (Sequential Structure Alignment Program) http://www.cathdb.info/
The CATH Hierarchy and Classification • Class, C-level • Based on the secondary structure content of • the domain • There are four classes: • mainly-alpha, • mainly-beta, • alpha-beta, • (a combination of / and + in SCOP) • low secondary structure content http://www.cathdb.info/
The CATH Hierarchy and Classification • Architecture, A-level • This level describes the overall shape of the domain structure as determined by the orientations of the secondary structures but ignores the connectivity between the secondary structures. • It is assigned manually using a simple description of the secondary structure arrangement . http://www.cathdb.info/
The CATH Hierarchy and Classification • Topology (Fold family), T-level • Members in the fold family share the same overall shape and connectivity of the secondary structures in the domain core. • Domains in the same fold group may have different structural decorations to the common core. http://www.cathdb.info/
The CATH Hierarchy and Classification Topology (Fold family), T-level.3.40.30.xx
The CATH Hierarchy and Classification • Homologous Superfamily, H-level • Protein domains in each H-group are thought to share a common ancestor and are homologous. • Similarities are identified either by high sequence identity or structure similarity using SSAP. Domains are classified in the same homologous superfamily if they satisfy one of the following criteria: • Sequence identity >= 35%, overlap >= 60% of larger structure equivalent to smaller. • SSAP score >= 80.0, sequence identity >= 20%, 60% of larger structure equivalent to smaller. • SSAP score >= 70.0, 60% of larger structure equivalent to smaller, and domains which have related functions, which is informed by the literature and Pfam protein family database (Bateman et al., 2004). • Significant similarity from HMM-sequence searches and HMM-HMM comparisons using SAM (Hughey &Krogh, 1996), HMMER (http://hmmer.wustl.edu) and PRC (http://supfam.org/PRC).
The CATH Hierarchy and Classification Sequence Family Levels: (S,O,L,I,D) Domains within each H-level are subclustered into sequence families using multi-linkage clustering at the following levels: ***The D-level is assigned as a counter within each S100 family to ensure that each domain in CATH has a unique CATHSOLID classification http://www.cathdb.info/
Not completely manual: SCOP Workflow Andreeva, et al, NAR, 2008
SCOP: Structural Classification of Proteins Family: Clear evolutionarily relationship (1) pairwise residue identities between the proteins are 30% and greater. (2) Proteins with low sequence similarity but very similar functions and structures; for example, many globins have sequence identities of only 15%. Superfamily: Probable common evolutionary originProteins that have low sequence identities, but whose structural and functional features suggest that a common evolutionary origin is probable are placed together in superfamilies. For example, actin, the ATPase domain of the heat shock protein, and hexakinase together form a superfamily. Fold: Major structural similarity(1) have same major secondary structures in same arrangement and with the same topological connections. (2) Proteins placed together in the same fold category may not have a common evolutionary origin: the structural similarities could arise just from the physics and chemistry of proteins favoring certain packing arrangements and chain topologies. Class:secondary structure content and organization Murzin et al. J. Mol. Biol. 247, 536-540, 1995
Common Folds • Tim barrel fold • /β protein fold • Named after glycolytic enzyme triosephosphateisomerase • Eight α-helices and eight parallel β-strands • 33 SCOP superfamilies • Immunoglobulin fold • All-β protein sandwich • Consists of 2 layers • ~7 antiparallel β-strands arranged in two β-sheets • 28 SCOP superfamilies • Rossman fold • /β protein fold • Named after Michael Rossman • Parallel β-strands connected by -helices • 12 SCOP families
Common Folds “CATH – A hierarchic classification of protein structure domains” Oregngo et al., Structure, 5: 1093-1108, 1997.
Immunoglobulin-like beta-sandwich VL CL VH CH1 CH2 CH3 Antibody domains CuZn Superoxide Dismutase
Red = Rossman fold domain within the enzyme alcohol dehydrogenase
Rossman fold TIM-Barrel fold
TIM-barrel 33 different superfamilies that share the same fold
Aldolase Enolase
SCOP CATH
SCOP vs. CATH The number of domains into which each chain is separated in S C O P and CATH is compared. For the most part, the two classification schemes agree on the number of domains per chain (5681 of 6875 chains is ∼82% agreement). However, in the case of chains split into two domains in CATH, almost half are considered as only one domain within S C O P. “A systematic comparison of protein structure classifications: SCOP, CATH and FSSP” Caroline Hadleyand David T Jones, Structure, 7(9): 1099-1112 , 1999
SCOP vs. CATH SCOP: small protein CATH: mainly • CATH ignores the presence of small β strands in the lysozymesuperfamily and considers the protein mainly α • SCOP takes into account the functional and evolutionary importance of these strands, and classifies the lysozymesα/β. “A systematic comparison of protein structure classifications: SCOP, CATH and FSSP” Caroline Hadleyand David T Jones, Structure, 7(9): 1099-1112 , 1999
The Russian doll effect The recurrence of common motifs within many of the superfolds and major architectures gives rise to an overlap of structures in these regions of fold space. This means that it becomes harder to distinguish between structural families for these architectures and it is perhaps more appropriate to consider a continuum of protein folds. This is particularly apparent in the layer-based sandwich architectures of the mainly β and α−β classes. For example, within the α−β three-layer doubly wound architectures, it is possible to generate a very large family of structures. Each new structure added to a family will be related to the last by a simple extension of one or more βαβ motifs and the structures are then embedded within each other in a ‘Russian doll’ like effect. “CATH – A hierarchic classification of protein structure domains” Oregngo et al., Structure, 5: 1093-1108, 1997.
Meaning, the designations implied below aren’t so definitive
Structural redundancy (563) (423) (283) AN ASIDE: Commonly, SCOP/CATH classifications are used to remove structural redundancy from a dataset. For example, the plots are above are from a paper that my lab published characterizing a catalytic site prediction algorithm.